

快科技 12 月 3 日消息,Intel 今天正式发布了代号 的第二代锐炫 B 系列显卡,首发两型号锐炫 B580、B570,而此时距离第一代 A 系列最初登场已经两年多了。
两款新品定位主流市场,主要面向 2K 超高画质游戏玩家,大致对标 RTX 4060 系列、AMD RX 7600 系列。
因为根据 Intel 提供的数据,1080p 在游戏玩家中的占比逐年递减,如今已经降至 56%,2K 分辨率则增长到了 22%,预计到 2026 年即可实现反超。

这一代,Intel 主打三个亮点:最佳性价比、XeSS 2、AI 加速。我们会逐一和大家介绍。
新的 Xe2 架构在前代 Xe 基础上进行大量的优化改进,尤其是投入了大量精力对架构的兼容性和软件开销进行重构和优化。
Xe2 不仅进一步提升了软件的适配性,还增强了架构的效率,提高了资源利用率,特别是减轻了软件对硬件的开销。

先来看一下两款新卡的公版规格,后边再讲架构和技术。
锐炫 B580 配备了 20 个新一代 Xe2 核心 ( 分为 5 个切片 ) ,对比上代 A580 反而少了 4 个核心与 1 个切片,同时有 20 个光追单元、160 个 XXM AI 引擎。
不过,核心频率从 大幅提高到 ,弥补了核心数量的不足,INT8 算力性能从 197 TOPS 来到了 233 TOPS,提升幅度约 18%。
显存位宽从 256-bit 降至 192-bit,但是容量从 8GB GDDR6 扩大到 12GB GDDR6,等效频率也从 16GHz 提高到 19GHz,因此带宽从 512GB/s 略微降至 456GB/s。
整卡功耗 190W,只增加了区区 5W,从而大大提高了能效比,只需单个 8 针供电。
锐炫 B570 做了一部分精简,配备 18 个 Xe2 核心、18 个光追单元、144 个 XMX 引擎,核心频率略降至 ,INT8 算力性能 203 TOPS。
搭配 160-bit 10GB GDDR6 显存,等效频率依然是 19GHz,带宽 380GB/s,整卡功耗仅为 150W。
系统总线接口很遗憾并不是 PCIe 5.0,而且从 PCIe 4.0 x16 砍半为 PCIe 4.0 x8,当然对这种级别的卡来说影响可以忽略不计。
硬件解码支持 AV1、HEVC ( H.265 ) 、AVC ( H.264 ) 、VP9、XAVC-H,但是不支持更新的 VVC ( H.266 ) 。
视频输出支持 HDMI 2.1、 2.1 UHBR 13.5 ——上代是 DP 2.0 UHBR 10。
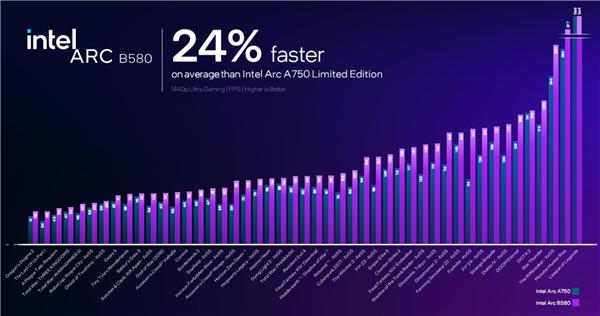
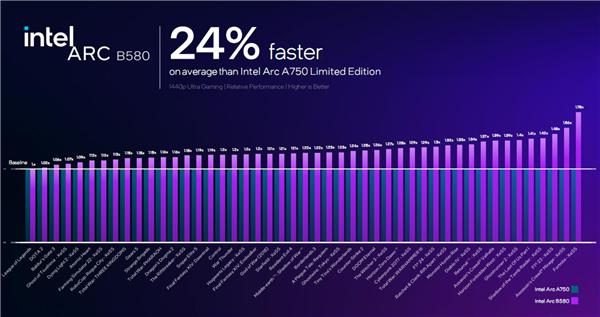
官方宣称,锐炫 B580 对比定位更高的锐炫 A750,平均性能提升幅度可达 24%。
特别是打开 XeSS 之后,提升更加明显,《堡垒之夜》甚至可达 78%,《刺客信条:幻景》也能有 56%。
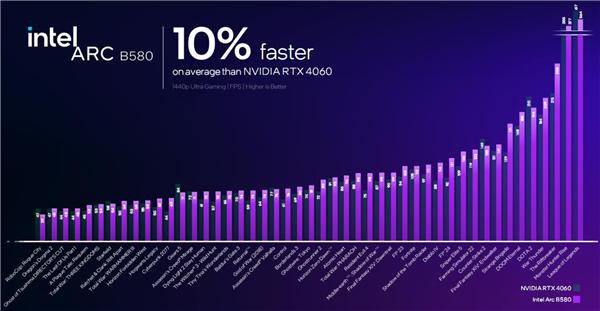
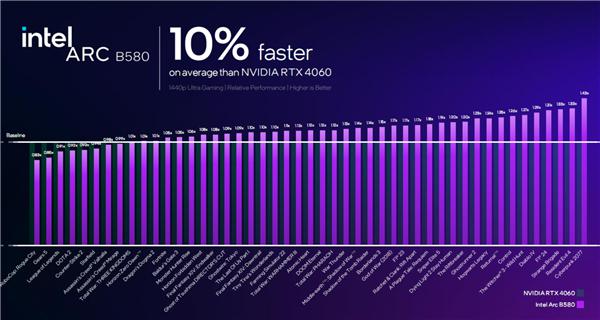
对比竞品 RTX 4060,平均领先幅度为 10%,考虑到种种因素,可以大致视为二者基本在同一档次,和 RX 7600 也基本差不多。
没有达到之前预期的 RTX 4060 Ti 的水平,有点小遗憾。
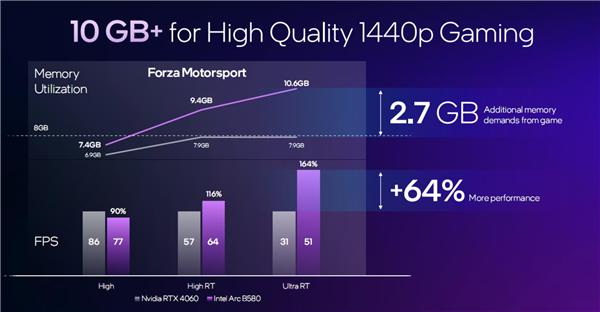
不过无论对比 RTX 4060 还是 RX 7600,锐炫 B580 的一个显著优势就是显存多了一半,在游戏中更不容易爆显存,运行 AI 负载时也更有余力。


这一次,Intel 依然打造了官方公版,也就是限量版。
仍旧是双风扇、双插槽、黑色风格,重点优化了散热设计,背面有一半都做了散热格栅,风流更大,噪音也更低。

首批合作伙伴除了老朋友宏碁、华擎、蓝戟、旌宇,还新增了两家,一是常年主打高性价比的铭瑄,二是新的傲世创科 ( Onix ) 。
各品牌普遍都做了双风扇、三风扇两种设计,除了宏碁暂时只有一款双风扇,傲世创科则都是双风扇。

锐炫 B580 显卡将于 12 月 13 日正式上市 ( 12 日晚评测解禁 ) ,定价 249 美元起。
要知道,锐炫 A750 两年多前首发的时候,还是要 289 美元。
锐炫 B570 显卡则要等到明年 1 月 16 日才会开卖,定价 219 美元起。

其实,Lunar Lake 即酷睿 Ultra 200V 系列处理器中已经率先应用 Xe2 架构的核显,也就是锐炫 140V、锐炫 130V,如今终于来到了桌面独立显卡,未来还会陆续进入笔记本独立显卡、车载方案、嵌入式方案等。
Intel 表示,Xe2 架构相对于初代,重点就是提升各方面的效率,包括更高的利用率、更好的负载分配、更好的软件开销等等。
同时,Xe 架构诞生两年多来,Intel 一直在努力完善驱动、游戏的生态支持,先后迭代了 50 多个版本的驱动,新游戏 0 日支持超过 120 款,游戏适配优化数量也比当初增加了 2.5 倍。


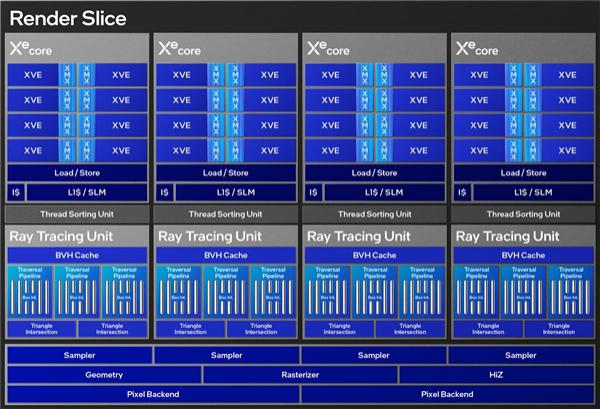
这就是 Xe2 的整体架构图,主体依然是渲染切片,这是整个 SoC 芯片的基本结构,配合指令前端、二级缓存构成一个整体,和第一代如出一辙,基本没啥变化。
每个渲染切片内包含 4 个 Xe 核心 ( 计算引擎 ) 、4 个光追单元,以及 4 个采样器、几何单元、光栅单元、HiZ 单元 ( 层次 Z ) 、两个像素后端等模块。
各个部分的具体变化,下边拆开来讲。

二代 Xe2 核心除了继续原生支持 指令,还增加了对 的支持,虽然不是原生,但执行 指令是没问题的,从而能够更好地分配计算资源,还支持 64 位原子操作。
每个 Xe 核心内部,包含 8 个 512 位的矢量引擎 ( XVE ) 、8 个 2048 位的 XMX 引擎,比上代减少了足足一半,可能调度效率会更高、更灵活。
这一次,Intel 为每个 Xe 核心加入了多达 256KB 容量的一级缓存、本地共享缓存 ( SLM ) ,大大减轻了对二级缓存的依赖。

XVE 矢量引擎除了支持 /,还支持矩阵扩展,包括 INT2、INT4、INT8、FP16、BF16、TF32 等数据类型,其中 TF32 是针对 AI 优化的数据格式还扩展了 Math、FP64 支持。
另外,它还支持三路并发,包括 FP、INT/EM、XMX,指令调度和执行效率更高。
对比初代,XVE 引擎现在更小巧 ( 基本可以视为砍半 ) ,应该也会更灵活。

光追部分,Intel 也做了大刀阔斧地改进,整体结构没太大变化,但是规模和性能高得多,比如遍历流水线从 2 条增至 3 条、方盒相交增大 1.5 倍、三角形相交增大 2 倍、BVH ( 包围盒层次结构 ) 缓存增大 2 倍来到 16KB。
这样的规模当然远远没法和 相比,甚至不如 AMD,但提升也是相当明显的,应该能够达到基本可用的水平,当然更有赖于游戏的适配和优化。

媒体引擎包含两个相同的多媒体解码器 ( MFX ) ,但注意它和 Lunar Lake 里集成的核显媒体引擎略有不同,没有 XMX 硬件编解码单元,因此不支持 VVC ( H.266 ) 硬解码。

这就是 BMG-G21,二代锐炫显卡首发的 GPU 核心芯片。
它总共有 5 个渲染切片、20 个 Xe2 核心、20 个光追单元、160 个 XMX 引擎、20 个纹理采样器、10 个像素后端,以及 2 个多格式 X 编解码器,还有多达 18MB 二级缓存、192 位显存。
各家的 GPU 架构设计不同,所以核心规模不具备直接可比性,但如果将这些与 GPU 类比,那就相当于 80 个 ROP 光栅单元、160 个 TMU 纹理单元。
这是因为,纹理采样器转换为 TMU 的比例是 1:8,像素后端与 ROP 的转换比例同样是 1:8。
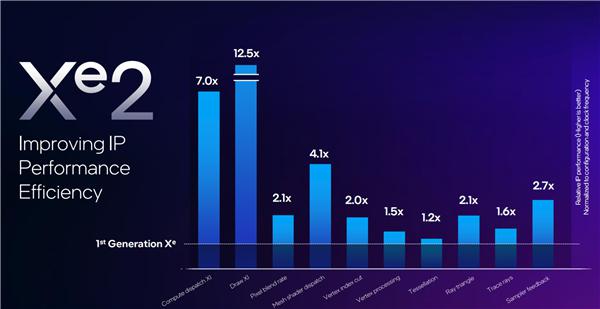
按照 Intel 的首发,经过优化的第二代 Xe 核心,性能提高了 70%,能效提高了 50%。
而在一组微基准测试中,性能提升幅度最高可达惊人的 12.5 倍。
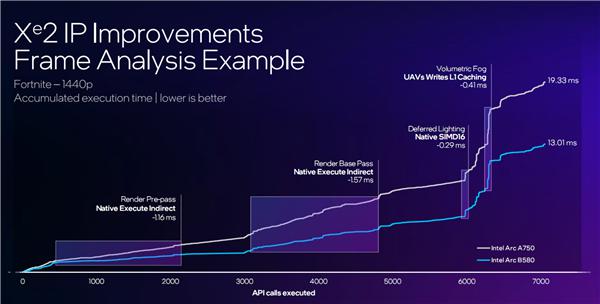
比如在《堡垒之夜》中,上图白线代表锐炫 A 系列,蓝线代表锐炫 B 系列,单位是毫秒,时间则越短越好。
锐炫 A 系列执行一帧渲染的时间为 19.33 毫秒,锐炫 B 系列则缩短到了 13.01 毫秒。
关键是,每一个渲染环节的效率都更高了,比如直接执行节省了 1.1 毫秒,间接执行节省了 1.5 毫秒等。
这也就证明,锐炫 B 系列的每一个地方都做了微架构优化,都可以节省渲染时间,从而提升渲染效率和性能。
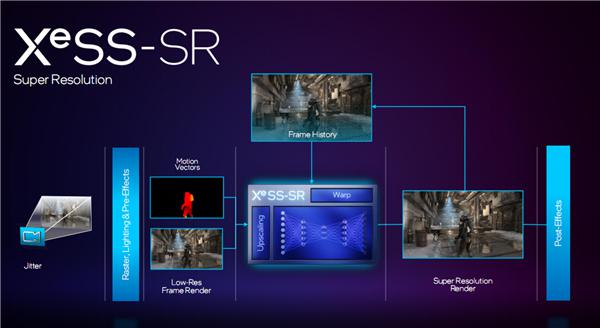

随着图形技术的进步,单纯的渲染已经不足以反应 GPU 计算能力,也无法做到显著提升性能,AI 渲染就越来越普遍。
XeSS 就是 Intel 打造的 AI 超分解决方案,对标 DLSS、AMD FSR,在较低分辨率的画面帧的基础上,提取运动矢量,使用超分辨率技术进行放大和加速,从而生成更高质量的图像。
官方号称,在 2K 超高画质游戏中,XeSS 可以带来 22-80%的性能提升,尤其是在光追等像素生成较为困难的场景中效果更明显。
经过不断努力,Intel XeSS 已经有超过 150 款游戏支持,初具规模。

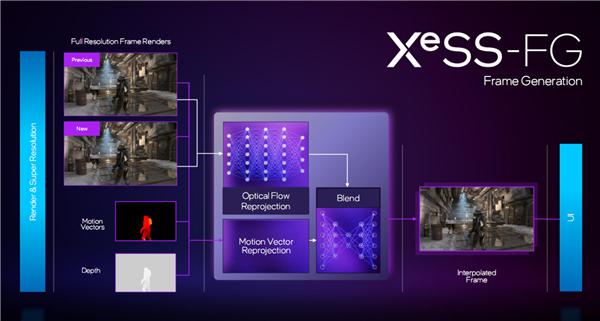
如今,XeSS 终于升级为第二代,SR 超分技术基础上增加了两项新技术:XeSS FG 帧生成技术,提升画面质量与帧率;XeLL 低延迟技术,提升响应速度。
XeSS FG 帧生成技术的工作原理是:首先使用游戏引擎,原生渲染出第一帧和第二帧,然后通过插帧技术和 AI 算法,生成二者之间的中间帧并插入。
为了实现这一目标,Intel 采用了两种技术,分别是光流重投影技术、运动矢量重投影技术,二者结合以确保插帧的准确性、画面的流畅性。
不过不同于 RTX 40 系列,Intel 不需要单独的光流加速器硬件,至于是否支持 、AMD 的显卡还在评估。
目前暂时还没有支持 XeSS FG 帧生成的游戏,毕竟刚刚宣布,但是《F1 24》等游戏已经在积极开发集成,UE 等游戏引擎也可以通过插件支持。
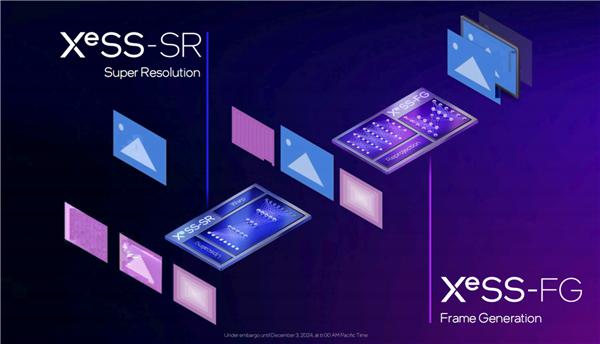
当然,XeSS SR 超分、XeSS FG 帧生成两项技术也是可以一起使用的。
XeSS SR 渲染一个稍低分辨率的画面帧,并将它放大,在送到 XeSS FG 插帧里,实现帧率翻倍。

比如《F1 24》,可以看到 XeSS 2 的性能提升是非常显著的,远超初代 XeSS。
2K 超高画质下,锐炫 B580 的基准帧率为 48FPS,开启 XeSS 2 质量模式就能提升至 2.8 倍,不但比初代 XeSS 高了超过 65%,甚至超过了 XeSS SR 超高性能模式。
依次开启 XeSS 2 平衡模式、性能模式、超高性能模式,帧率还可以逐步提升,最终高达 ,是原生性能的几乎 4 倍。
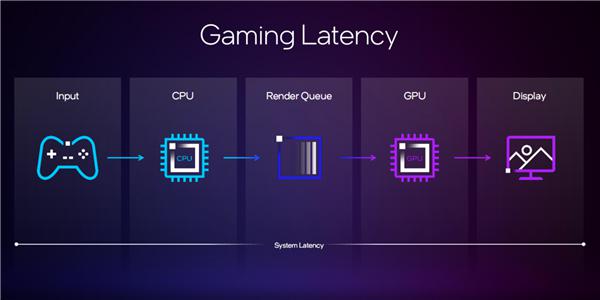
介绍 XeLL 低延迟技术之前,先回顾一下 PC 游戏中的系统延迟怎么来的。
这个过程始于玩家点击鼠标的动作,一直持续到画面最终显示在屏幕上,这个过程所需要的时间,就是我们说的延迟。
具体来说,玩家操作的信号首先传递给 CPU,随后进入一个称作渲染队列的环节,然后 GPU 将这些指令转换成屏幕上的像素,最后这些像素构成的图像呈现在显示器上。
整个流程中的每一步都可能增加延迟,累积起来就是我们在游戏中感受到的卡顿现象。
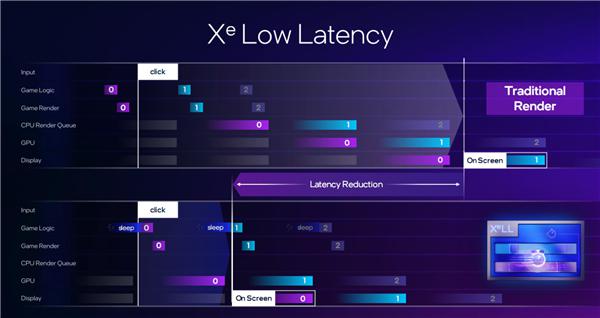
为了尽可能降低延迟, 打造了 技术,AMD 则推出了两代 Anti-Lag,现在轮到了 Intel XeLL。
XeLL 重点针对 CPU 渲染队列等待过程,基本消除了它,从而大大缩短了从鼠标点击到屏幕显示的整个过程。

Intel 工具已经可以显示具体延迟,方便玩家测量从鼠标输入到系统显示的整个延迟时间。
同时,Intel 内部还开发了延迟测量工具 ( LMT ) ,基于微控制器的一款特殊设备。
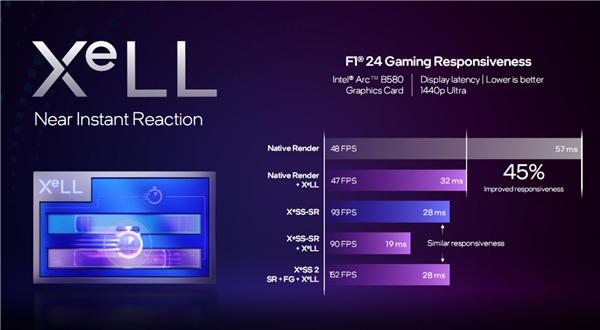
实际性能如何呢?还是以《F1 24》为例。
原生渲染时,48FPS 帧率的延迟是 57 毫秒,而在开启 XeLL 之后,延迟降低到了 32 毫秒,改善了多达 45%。
更神奇的是,如果把 XeSS SR、FG、XeLL 低延迟全部打开,可以把延迟降至 28 毫秒,改善 51%,同时帧率高达 ,提升 2.17 倍。
当然,也可以只开启 SR、低延迟,此时延迟仅有 19ms,改善足有 67%,而帧率为 90FPS,仍有原生渲染的接近 2 倍。
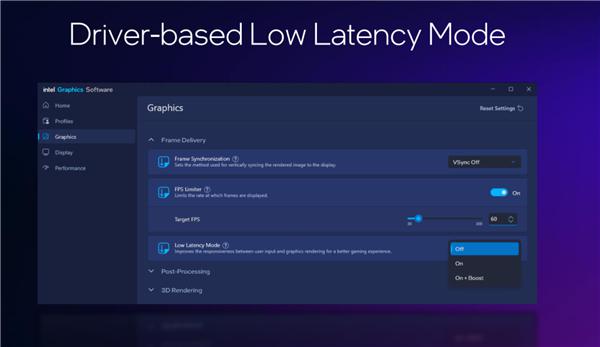

XeLL 低延迟技术是基于驱动程序实现的,因此效果不是最好的,但很容易集成到游戏中。
首发支持的有《F1 24》、《漫威暗夜之子》、《刺客信条:幻景》等等,未来还会有更多加入。
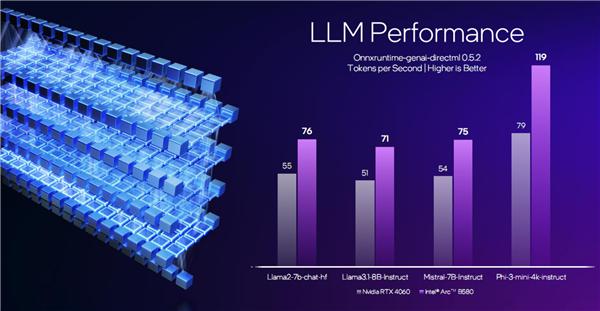
AI,尤其是生成式 AI,是如今 GPU 绕不开的话题,锐炫 B 系列也通过增强的 XMX 引擎,提供了更好的支持。
锐炫 B580 对比 RTX 4060,运行常见的 Llama 2、Llama 3.1、、Phi-3 等大型语言模型,都有相当大的性能优势,最多领先约 50%。
Intel 之前还推出了一个免费的生成式 AI 工具 AI 2.0,专为 Xe2 架构而来 ( 包括核显 ) 。
它允许用户在本地端侧体验图像创建、编辑、AI 对话等,下载模型即可体验,无需连接云端。

好的显卡,除了好的硬件架构技术,更离不开好的驱动,Intel 也在持续完善,功能不断丰富,无论是图形设置、3D 设置,还是超频,该有的都有。

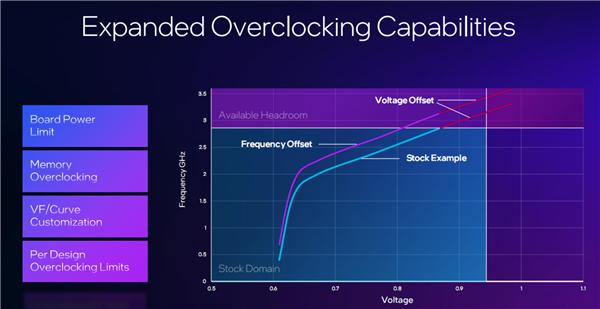
说到超频,锐炫 B 系列当然也可以,而且更简单,在驱动中开启高级模式即可操作。
上图中,浅蓝色显示的是默认频率和电压曲线,玩家可以向上推动该曲线,从而提升频率,获得更高的性能。
玩家还可以使用电压偏移来改变电压,并访问更多电压点,这一切都实时可见。
电压、功耗都可以设置一定的最高阈值,确保安全超频。
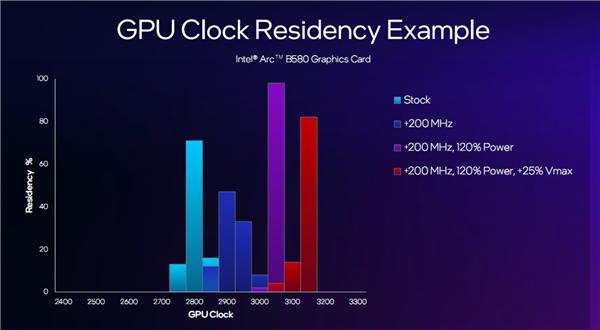
以锐炫 B580 为例,默认状态下即可轻松超频 ;增加 20%功耗可以再超 ;继续增加 25%电压还能继续超 。
当然,具体超频幅度和电压、功耗设置,取决于显卡的不同个体体质,以及散热等外部因素。
———END———
限 时 特 惠: 本站每日持续更新海量各大内部创业教程,永久会员只需109元,全站资源免费下载 点击查看详情
站 长 微 信: nanadh666

