

本文作者为的原班人马,其中第一作者王兆植是中国科学院大学和鹏城实验室的2022级联合培养博士生,共同一作刘悦是中国科学院大学2021级直博生。他们的主要研究方向是视觉模型设计和自监督学习。
如何突破 的 机制?中国科学院大学与鹏城国家实验室提出基于热传导的视觉表征模型 vHeat。将图片特征块视为热源,并通过预测热传导率、以物理学热传导原理提取图像特征。相比于基于机制的视觉模型, vHeat 同时兼顾了:计算复杂度(1.5次方)、全局感受野、物理可解释性。
vHeat-base 模型在高分辨率图像输入时,、GPU 显存占用、flops 分别是 Swin-base 模型的3倍、1/4、3/4,在图像分类、目标检测、语义/实例分割等基础下游任务上达到了先进的性能表现。

论文地址:
代码地址:
论文标题:vHeat: upon Heat
CNN 和视觉 (ViT)是当前最主流的两类基础视觉模型。然而,CNN的性能表现受限于局部感受野和固定的卷积核算子。ViT 具有全局依赖关系的表征能力,然而代价是高昂的二次方级别计算复杂度。我们认为 CNN 和 ViT 的卷积算子和自注意力算子都是特征内部的像素传播过程,分别是一种信息传递的形式,这也让我们联想到了物理领域的热传导。于是我们根据热传导方程,将视觉语义的空间传播和物理热传导建立联系,提出了一种 1.5 次方计算复杂度的视觉热传导算子(Heat , HCO),进而设计出了一种兼具低复杂度、全局感受野、物理可解释性的视觉表征模型 vHeat。HCO 与 self- 的计算形式和复杂度对比如下图所示。实验证明了 vHeat 在各种视觉任务中表现优秀。例如 vHeat-T 在 -1K 上达到 82.2% 的分类准确率,比 Swin-T 高 0.9%,比 Vim-S 高1.7%。性能之外,vHeat 还拥有高推理速度、低 GPU 显存占用和低 FLOPs 这些优点。在输入图像分辨率较高时,base 规模的 vHeat 模型相比于 Swin 达到 3 倍吞吐量、1/4 的GPU显存占用和 3/4 的 FLOPs。
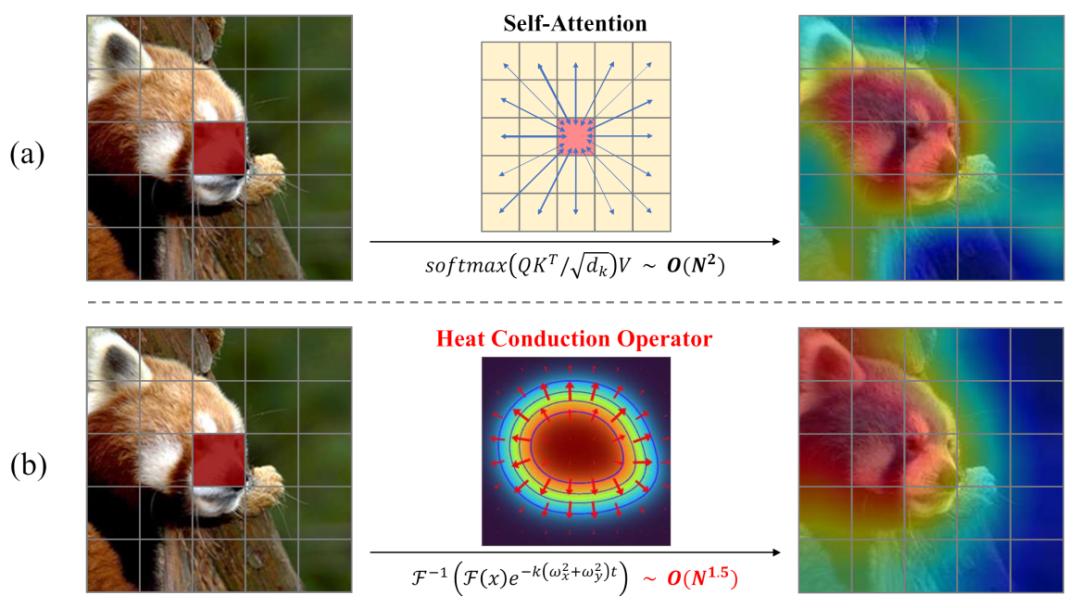
方法介绍
用
表示点
在 t 时刻下的温度, 物理热传导方程为
,其中 k>0,表示热扩散率。给定 t=0 时刻下的初始条件
,该热传导方程可以采用傅里叶变换求得通解,表示如下:
其中
和
分别表示傅里叶变换和逆傅里叶变换,
表示频域空间坐标。
我们利用 HCO 来实现视觉语义中的热传导,先将物理热传导方程中的
扩展为多通道特征
,将
视为输入,
视为输出,HCO 模拟了离散化形式的热传导通解,如下公式所示:
其中
和
分别表示二维离散余弦变换和逆变换,HCO 的结构如下图 (a) 所示。
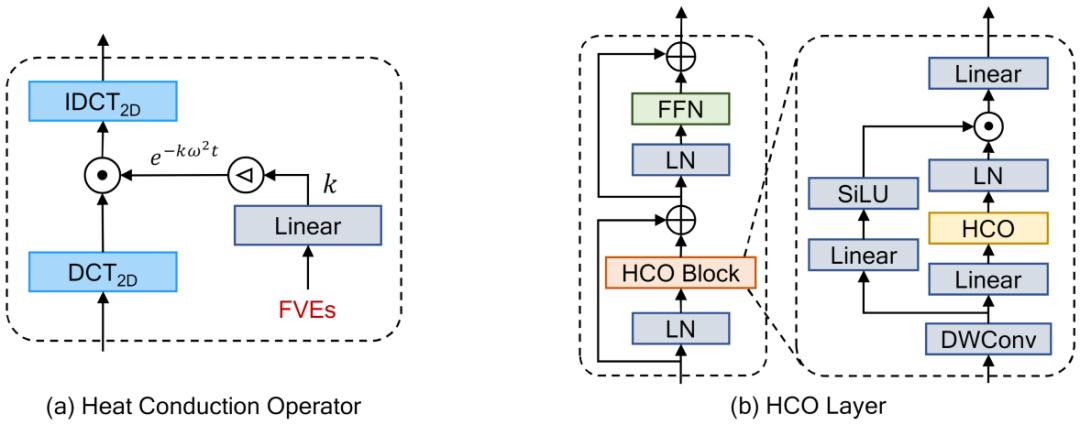
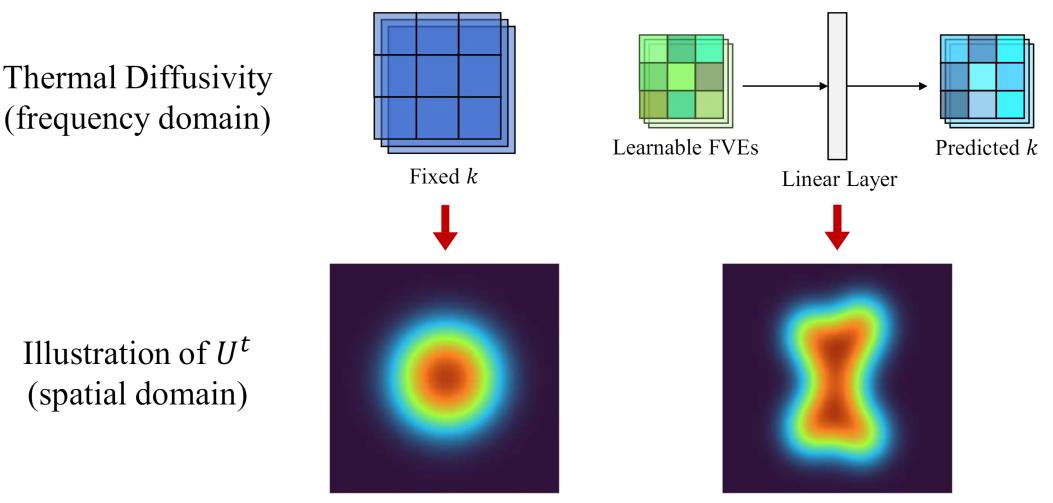
此外,我们认为不同图像内容应该对应不同的热扩散率,考虑到
的输出在频域中,我们根据频率值来决定热扩散率,
。由于频域中不同位置表示了不同的频率值,我们提出了频率值编码( Value , FVEs)来表示频率值信息,与 ViT 中的绝对位置编码的实现和作用类似,并用 FVEs 对热扩散率 k 进行预测,使得 HCO 可以进行非均匀、自适应的传导,如下图所示。
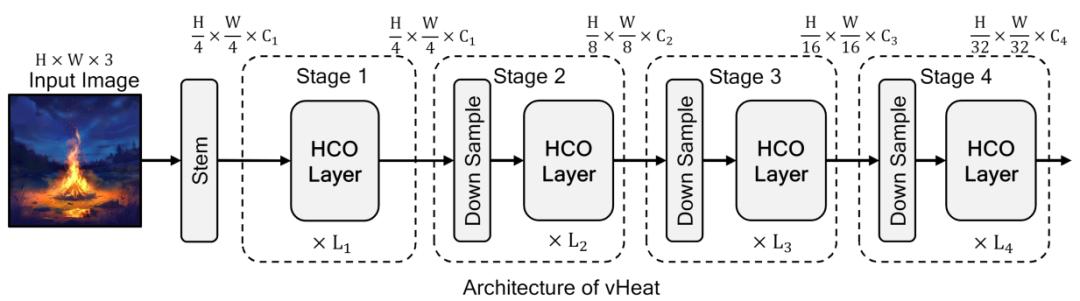
vHeat 采用多层级的结构实现,如下图所示,整体框架与主流的视觉模型类似,其中的 HCO layer 如图 2 (b) 所示。
实验结果
分类
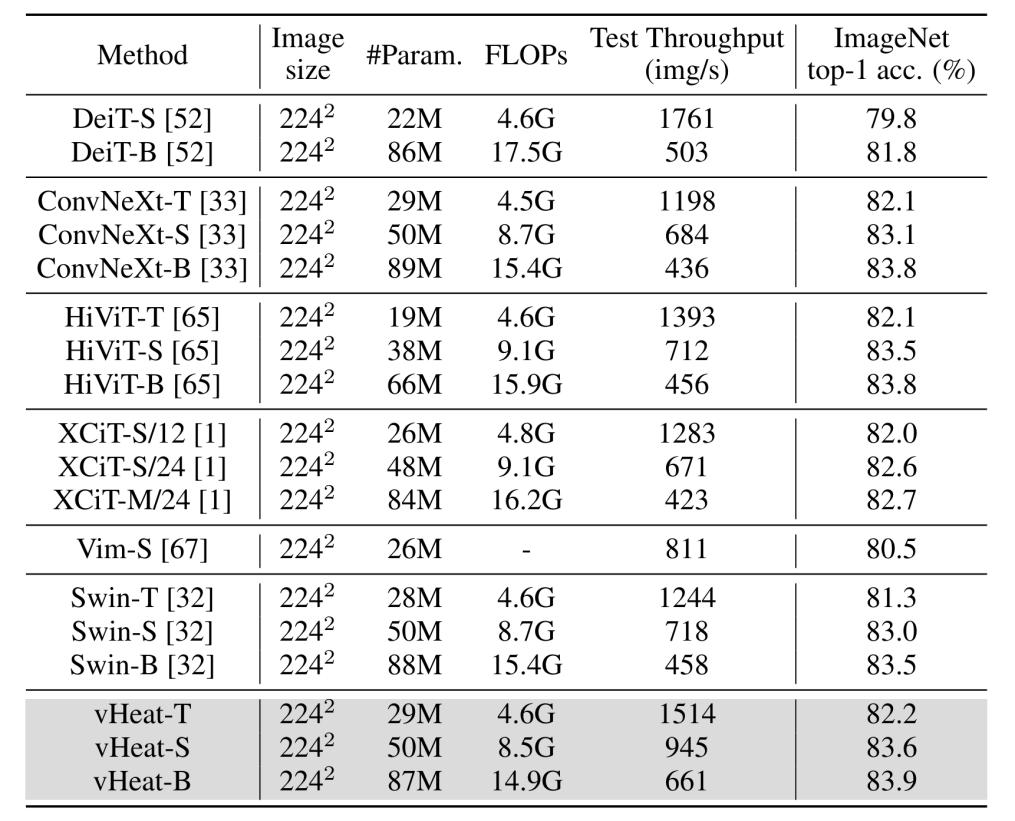
通过对比实验结果不难看出,在相似的参数量和 FLOPs 下:
vHeat-T 取得了 82.2% 的性能,超过 DeiT-S 达 2.4%、Vim-S 达 1.7%、Swin-T 达 0.9%。
vHeat-S 取得了 83.6% 的性能,超过 Swin-S 达 0.6%、-S 达 0.5%。
vHeat-B 取得了 83.9% 的性能,超过 DeiT-B 达 2.1%、Swin-B 达 0.4%。
同时,由于 vHeat 的 O (N^1.5) 低复杂度和可并行计算性,推理吞吐量相比于 ViTs、SSM 模型有明显的优势,例如 vHeat-T 的推理吞吐量为 1514 img/s,比 Swin-T 高 22%,比 Vim-S 高 87%,也比 -T 高 26%,同时拥有更好的性能。
下游任务
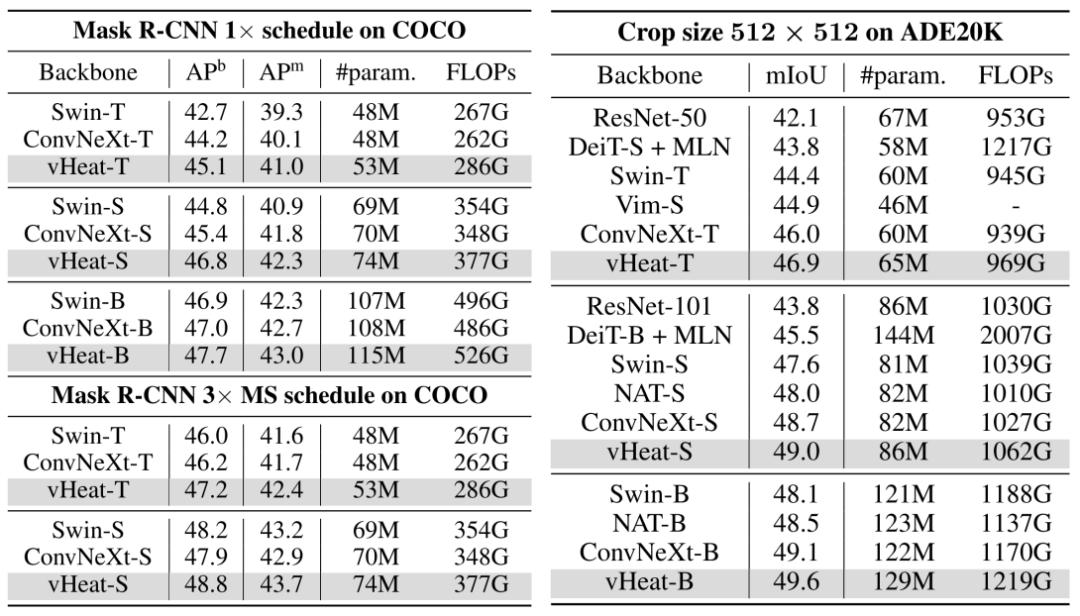
在 COCO 数据集上, vHeat 也拥有性能优势:在 fine-tune 12 的情况下,vHeat-T/S/B 分别达到 45.1/46.8/47.7 mAP,超过了 Swin-T/S/B 达 2.4/2.0/0.8 mAP,超过 -T/S/B 达 0.9/1.4/0.7 mAP。在 数据集上,vHeat-T/S/B 分别达到 46.9/49.0/49.6 mIoU,相比于 Swin 和 依然拥有更好的性能表现。这些结果验证了 vHeat 在视觉下游实验中完全 work,展示出了能平替主流基础视觉模型的潜力。
分析实验
有效感受野
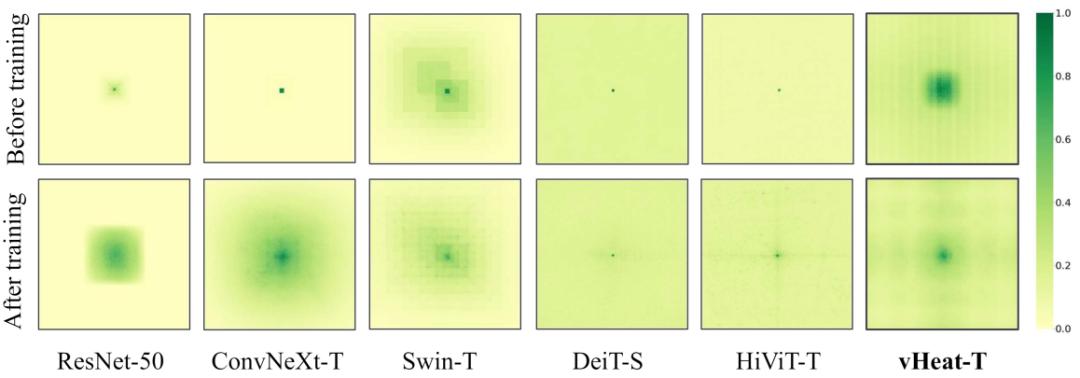
vHeat 拥有全局的有效感受野,可视化对比的这些主流模型中只有 DeiT 和 HiViT 也具备这个特性。但是值得注意的是,DeiT 和 HiViT 的代价是平方级的复杂度,而 vHeat 是 1.5 次方级的复杂度。
计算代价
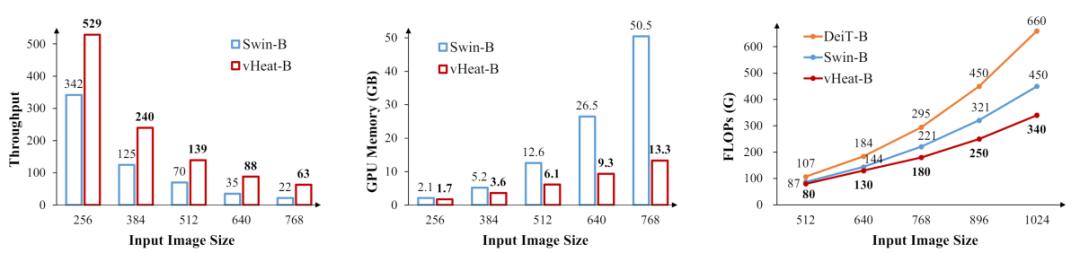
上图从左到右分别为 vHeat-B 与其他 base 规模下的 ViT-based 模型的推理吞吐量 / GPU 显存占用 / 计算量 FLOPs 对比。可以明显看出,由于 O (N^1.5) 的计算复杂度,vHeat 相比于对比的模型有更快的推理速度、更低的显存占用以及更少的 FLOPs,并且在图像分辨率越大时,优势会更为明显。在输入图像为 768*768 分辨率时,vHeat-B 的推理吞吐量为 Swin-B 的 3 倍左右,GPU 显存占用比 Swin-B 低 74%,FLOPs 比 Swin-B 低 28%。vHeat 与 ViT-based 模型的计算代价对比,展示出其处理高分辨率图像的优秀潜质。
© THE END
———END———
限 时 特 惠: 本站每日持续更新海量各大内部创业教程,永久会员只需109元,全站资源免费下载 点击查看详情
站 长 微 信: nanadh666

