

1. 异常突起
HBase 集群的某一个 的 CPU 使用率突然飙升到百分之百,单独重启该 之后,CPU 的负载依旧会逐渐攀上顶峰。多次重启集群之后,CPU 满载的现象依然会复现,且会持续居高不下,慢慢地该 就会宕掉,慢慢地 HBase 集群就完犊子了。
2. 异常之上的现象
CDH 监控页面来看,除 CPU 之外的几乎所有核心指标都是正常的,磁盘和网络 IO 都很低,内存更是充足,压缩队列,刷新队列也是正常的。
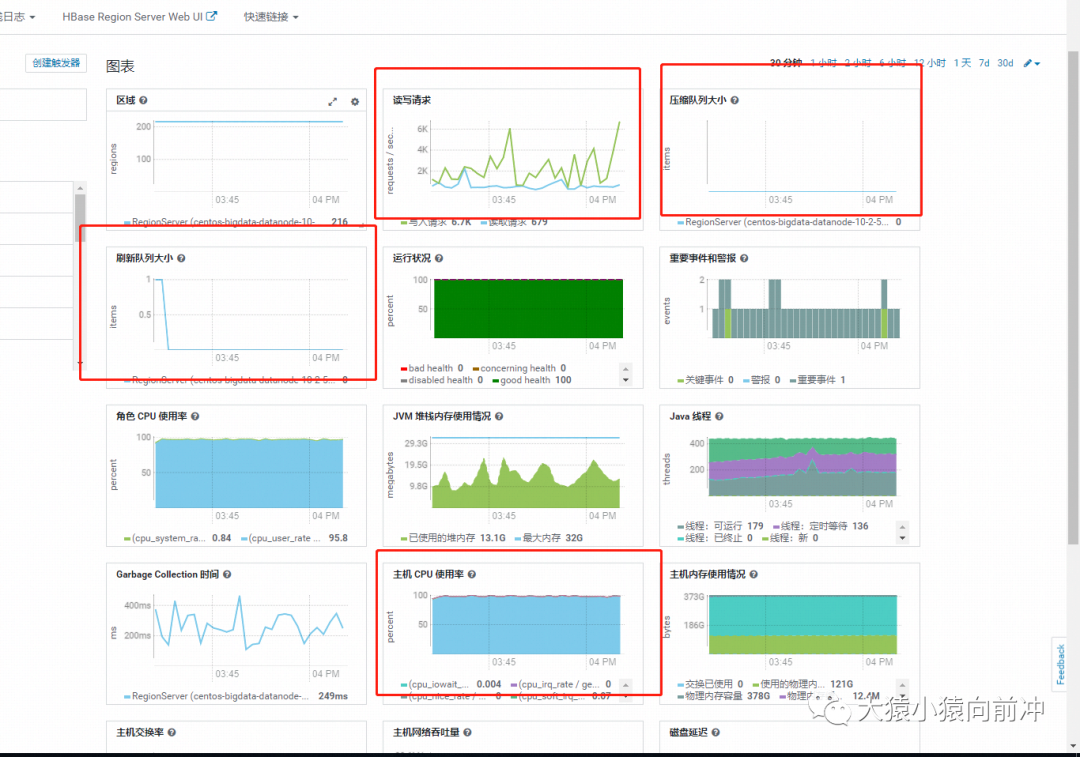
普罗米修斯的监控也是类似这样的,就不贴图了。
监控指标里的数字,只能直观地告诉我们现象,不能告诉我们异常的起因。因此我们的第二反应是看日志。
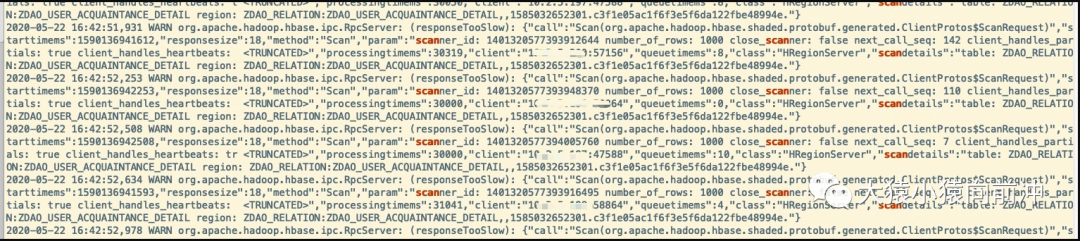
(企业微信截图)
与此同时,日志中还有很多类似这样的干扰输出。

后来发现这样的输出只是一些无关紧要的信息,对分析问题没有任何帮助,甚至会干扰我们对问题的定位。
但是,日志中大量 scan 的警告信息,似乎在告诉我们,HBase 的 内部正在发生着大量耗时的 scan 操作,这也许就是 CPU 负载高的元凶。可是,由于各种因素的作用,我们当时的关注点并没有在这个上面,因为这样的信息,我们在历史的时间段里也频繁撞见。
3. 初识
监控和日志都不能让我们百分百确定 CPU 负载高是由哪些操作引起的,我们用 top 命令也只能看到 HBase 这个进程消耗了很多 CPU,就像下图看到的这样。
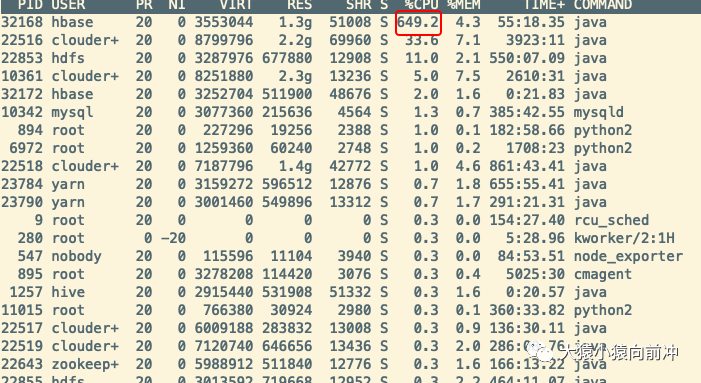
如果不做进一步分析,你仍然不知道,问题出现在 HBase 相关进程下的哪些执行线程。Java 中分析进程的命令,可以使用 或 jstat 等。但是,今天要介绍的主角不是这俩,甚至不是 async-,而是 。async- 虽然也是一个很强大的工具,但是 包含了它,且功能更强大,堪称神器。
很早以前就听说过,起初以为它只能用来分析 WEB 应用,例如 Boot,这两天仔细翻看其官方文档之后,才觉得自己是多么的无知。 的相关介绍和入门使用,请参考其文档,它的官方文档比任何第三方资料都详细和友好。
4. 用 来分析 HBase 的异常进程
4.1 运行
java -jar /data/arthas/arthas-boot.jar --target-ip 0.0.0.0
4.2 运行成功的界面
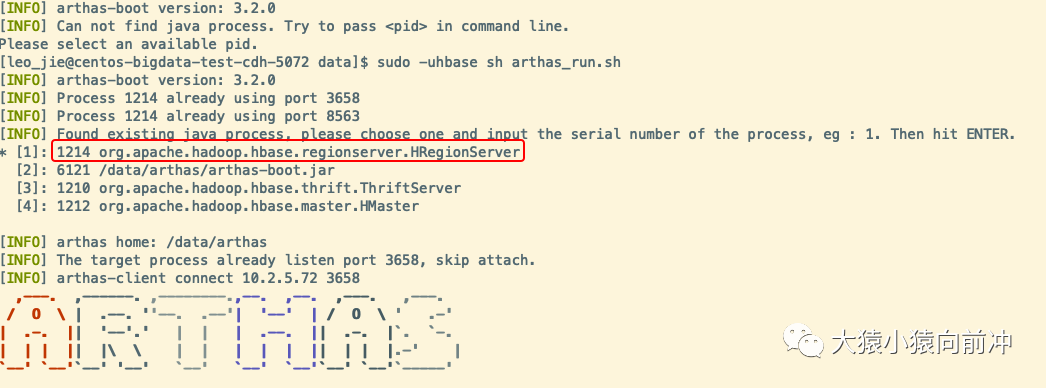
命令 top 定位到的异常的 HBase 进程 ID 是 1214,该进程就是 的进程。输入序号 1,回车,就进入了监听该进程的命令行界面。
4.3
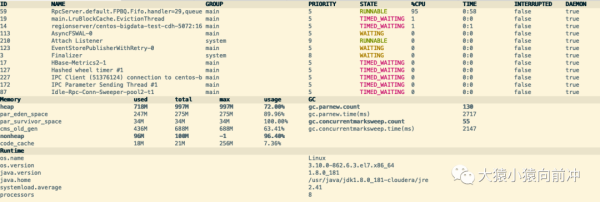
运行 命令回车,就可以查看该进程占用资源的总体情况,可以从图中看到,ID 为 59 的线程,占用的 CPU 最高。
4.4

输入 命令回车,查看该进程下所有线程的执行情况。
4.5 -n 3
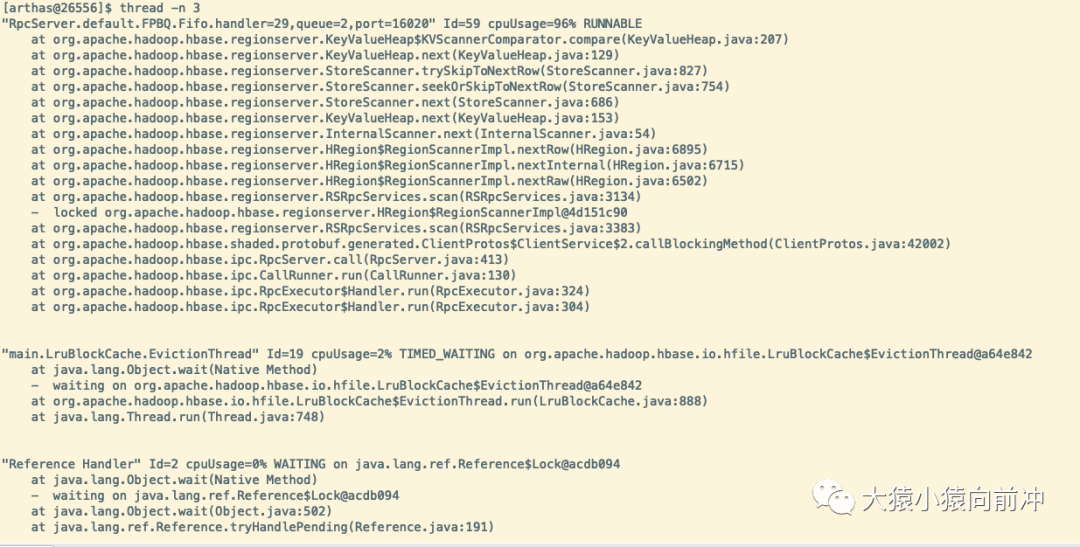
输出资源占用前三名的线程。
4.6 -n 3 -i 5000
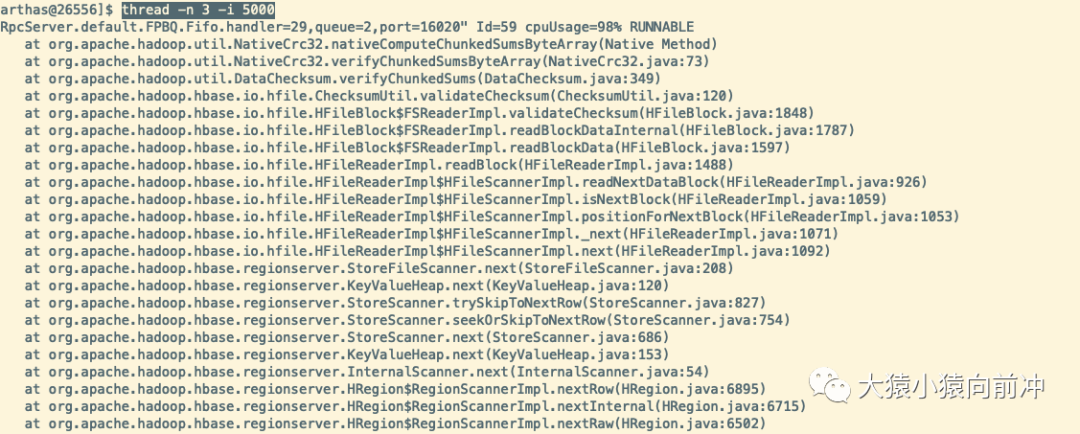
单位时间为 5 秒内,资源占用前三名的线程。
4.7 使用async-生成火焰图
生成火焰图的最简单命令。
profiler start
隔一段时间,大概三十秒。
profiler stop

在 web 里查看。
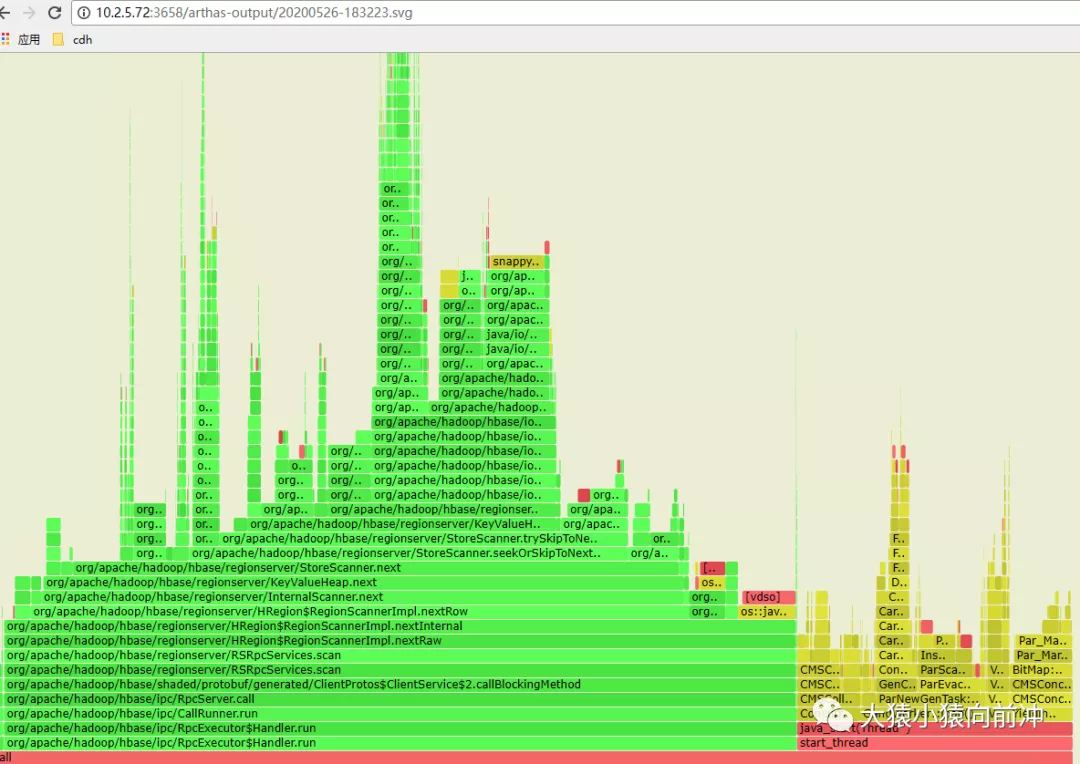
关于火焰图的入门级知识:
查看 jvm 进程 cpu 火焰图工具。
火焰图里很清楚地定位到 CPU 时间占用最高的线程是绿框最长的那些线程,也就是 scan 操作。
5. scan 操作引起的 CPU 负载过高
通过以上的进程分析,我们最终可以确定,scan 操作的发生,导致 CPU 负载很高。我们查询 HBase 的 API 基于 封装而成。
其实常规的 scan 操作是能正常返回结果的,发生异常查询的表也不是很大,所以我们排除了热点的可能。抽象出来业务方的查询逻辑是:
from happybase.connection import Connection
import time
start = time.time()
con = Connection(host='ip', port=9090, timeout=3000)
table = con.table("table_name")
try:
res = list(table.scan(filter="PrefixFilter('273810955|')",
row_start='x0fx10&Rxcaxdfx96xcbxe2xad7$xad9khEx19xfdxaax87xa5xddxf7x85x1cx81ku ^x92k',
limit=3))
except Exception as e:
pass
end = time.time()
print 'timeout: %d' % (end - start)
和 的组合是为了实现分页查询的需求, 的一堆乱码字符,是加密的一个 ,里面有特殊字符。日志中看到,所有的耗时查询,都有此类乱码字符的传参。于是,我们猜想,查询出现的异常与这些乱码字符有关。
但是,后续测试复现的时候又发现。
# 会超时
res = list(table.scan(filter="PrefixFilter('273810955|')",
row_start='27', limit=3))
# 不会超时
res = list(table.scan(filter="PrefixFilter('273810955|')",
row_start='27381095', limit=3))
也就是,即使不是乱码字符传参, 和 组合异常,也会导致 CPU 异常的高, 指定的过小,小于前缀,数据扫描的范围估计就会变大,类似触发了全表扫描, 势必会变大。
6. 频繁创建连接或使用线程池造成 scan 线程持续增长
我们操作 HBase 的公共代码是由 封装而成,其中还用到了 的线程池,在我们更深入的测试中又发现了一个现象,当我们使用连接池或在循环中重复创建连接时,然后用 监控线程情况,发现 scan 的线程会很严重,测试代码如下:
6.1 连接在循环外部创建,重复使用
from happybase.connection import Connection
import time
con = Connection(host='ip', port=9090, timeout=2000)
table = con.table("table")
for i in range(100):
try:
start = time.time()
res = list(table.scan(filter="PrefixFilter('273810955|')",
row_start='x0fx10&Rxcaxdfx96xcbxe2xad7$xad9khEx19xfdxaax87xa5xddxf7x85x1cx81ku ^x92k',
limit=3))
except Exception as e:
pass
end = time.time()
print 'timeout: %d' % (end - start)
程序开始运行时,可以打开 进入到 进程的监控,运行 命令,查看此时的线程使用情况:
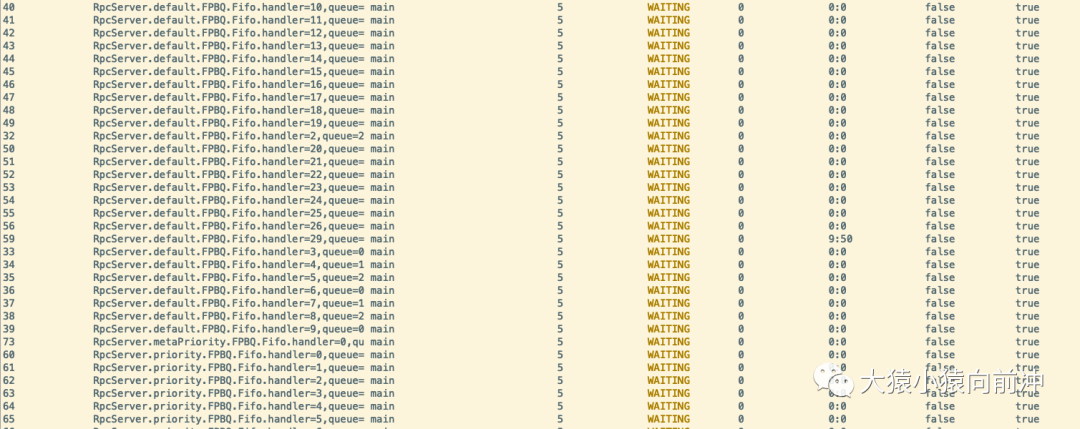
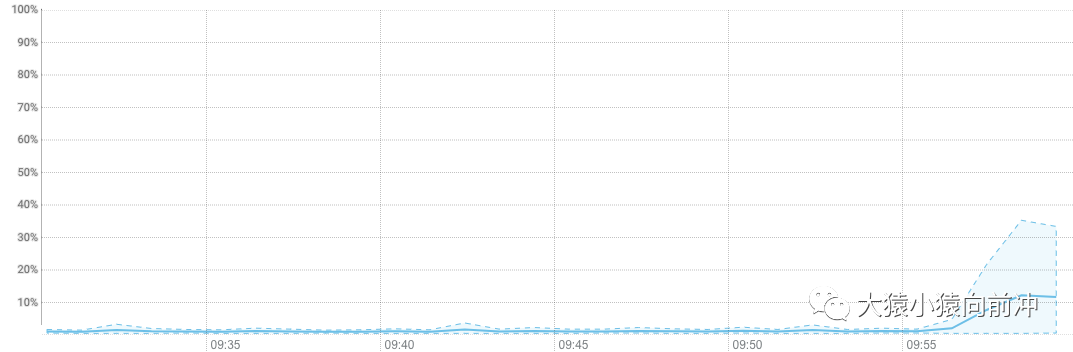
小部分在运行,大部分在等待。此时,CPU 的负载情况:
6.2 循环在内部频繁创建然后使用
代码如下:
from happybase.connection import Connection
import time
for i in range(100):
try:
start = time.time()
con = Connection(host='ip', port=9090, timeout=2000)
table = con.table("table")
res = list(table.scan(filter="PrefixFilter('273810955|')",
row_start='x0fx10&Rxcaxdfx96xcbxe2xad7$xad9khEx19xfdxaax87xa5xddxf7x85x1cx81ku ^x92k',
limit=3))
except Exception as e:
pass
end = time.time()
print 'timeout: %d' % (end - start)
下图中可以看到开始 的线程越来越多,CPU 的消耗也越来越大。

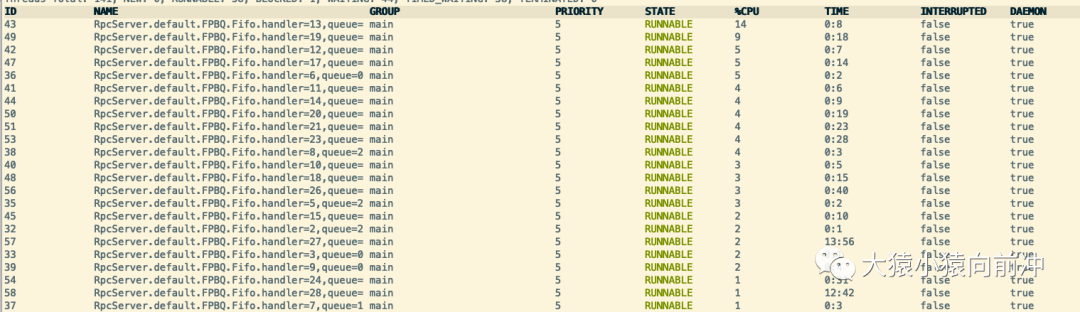
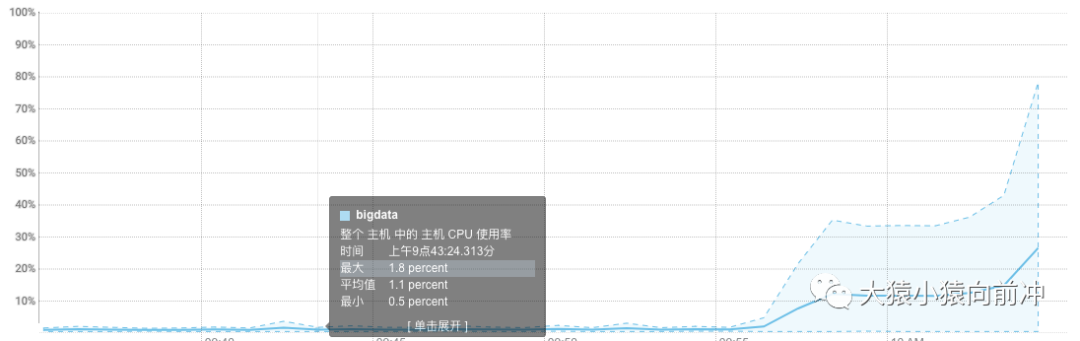
此时 CPU 的使用情况,由刚才的较为平稳,陡然上升:
6.3 连接池的方式访问 HBase
CPU 被之前的实验拉高,重启下集群使 CPU 的状态恢复到之前平稳的状态。然后继续我们的测试,测试代码:
没有超时时间
from happybase import ConnectionPool
import time
pool = ConnectionPool(size=1, host='ip', port=9090)
for i in range(100):
start = time.time()
try:
with pool.connection(2000) as con:
table = con.table("table")
res = list(table.scan(filter="PrefixFilter('273810955|')",
row_start='x0fx10&Rxcaxdfx96xcbxe2xad7$xad9khEx19xfdxaax87xa5xddxf7x85x1cx81ku ^x92k',
limit=3))
except Exception as e:
pass
end = time.time()
print 'timeout: %d' % (end - start)
如果不指定超时时间,会只有一个线程持续运行,因为我的连接池设置为 1。

CPU 的负载也不是太高,如果我的连接池设置的更大,或者我的并发加大,那么这些耗时 scan 的线程应该会更多,CPU 使用率也会飙升。
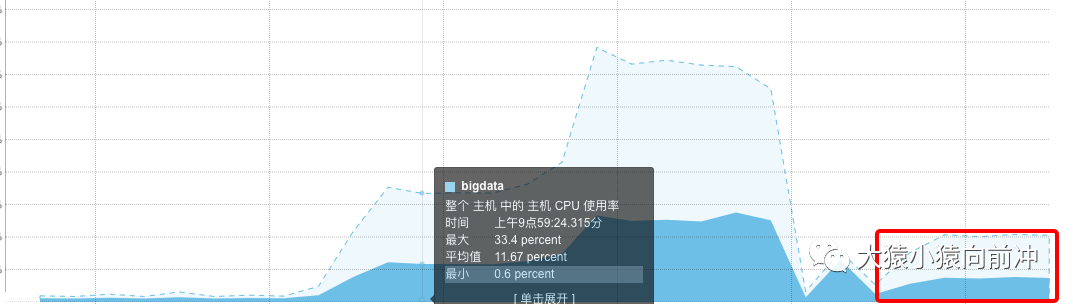
指定超时时间
from happybase import ConnectionPool
import time
pool = ConnectionPool(size=1, host='ip', port=9090, timeout=2000)
for i in range(100):
start = time.time()
try:
with pool.connection(2000) as con:
table = con.table("table")
res = list(table.scan(filter="PrefixFilter('273810955|')",
row_start='x0fx10&Rxcaxdfx96xcbxe2xad7$xad9khEx19xfdxaax87xa5xddxf7x85x1cx81ku ^x92k',
limit=3))
except Exception as e:
pass
end = time.time()
print 'timeout: %d' % (end - start)
此次测试中,我指定了连接池中的超时时间,期望的是,连接超时,及时断开,继续下一次耗时查询。此时,服务端处理 scan 请求的线程情况:

服务端用于处理 scan 请求的 状态的线程持续增长,并耗费大量的 CPU。
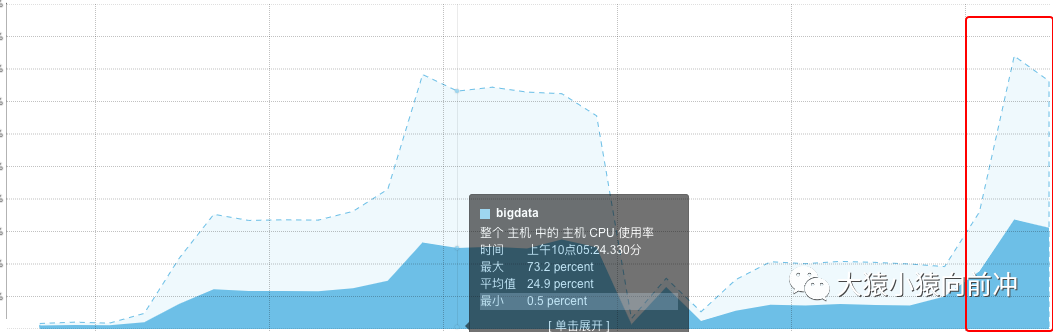
7. hbase…count
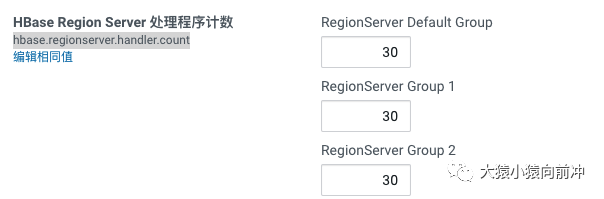
参考大神的博客,以及自己对这个参数的理解,每一个客户端发起的 RPC 请求(读或写),发送给服务端的时候,服务端就会有一个线程池,专门负责处理这些客户端的请求,这个线程池可以保证同一时间点有 30 个线程可运行,剩余请求要么阻塞,要么被塞进队列中等待被处理,scan 请求撑满了服务端的线程池,大量的耗时操作,把 CPU 资源消耗殆尽,其余常规的读写请求也势必大受影响,慢慢集群就完犊子了。
8. 控制 scan 请求占用很小的队列
首先,这个 hbase…count 的参数不能被调小,如果太小,集群并发高时,读写延时必高,因为大部分请求都在排队。理想情况是,读和写占用不同的线程池,在处理读请求时,scan 和 get 分别占用不同的线程池,实现线程池资源隔离。如果是我的话,第一反应可能也会简单、粗略地搞仨线程池,写线程池,get 线程池、scan 线程池。scan 线程池分配很小的核心线程,让其占用很小的资源,限制其无限扩张。但是真实的情况是这样吗?暂时,我还没仔细研究源码,HBase 提供了如下参数,可以满足读写资源分离的需求。
hbase…count
描述 在RegionServer上旋转的RPC侦听器实例数。主机将相同的属性用于主机处理程序的计数。过多的处理程序可能适得其反。使它成为CPU计数的倍数。如果大多数情况下是只读的,则处理程序计数接近cpu计数的效果很好。从两倍的CPU计数开始,然后从那里进行调整。 默认 30
hbase.ipc….
描述 确定呼叫队列数量的因素。值为0表示在所有处理程序之间共享一个队列。值为1表示每个处理程序都有自己的队列。 默认 0.1
hbase.ipc…read.ratio
描述
将呼叫队列划分为读写队列。指定的间隔(应在0.0到1.0之间)将乘以呼叫队列的数量。值为0表示不拆分呼叫队列,这意味着读取和写入请求都将被推送到同一组队列中。小于0.5的值表示读队列少于写队列。值为0.5表示将有相同数量的读取和写入队列。大于0.5的值表示将有比写队列更多的读队列。值1.0表示除一个队列外的所有队列均用于调度读取请求。示例:给定呼叫队列的总数为10,读比率为0表示:10个队列将包含两个读/写请求。read.ratio为0.3表示:3个队列将仅包含读取请求,而7个队列将仅包含写入请求。read.ratio为0.5表示:5个队列仅包含读取请求,而5个队列仅包含写入请求。read.ratio为0.8表示:8个队列将仅包含读取请求,而2个队列将仅包含写入请求。read.ratio为1表示:9个队列将仅包含读取请求,而1个队列将仅包含写入请求。
默认
0
hbase.ipc…scan.ratio
描述
给定读取呼叫队列的数量(根据呼叫队列总数乘以callqueue.read.ratio计算得出),scan.ratio属性会将读取呼叫队列分为小读取队列和长读取队列。小于0.5的值表示长读队列少于短读队列。值为0.5表示将有相同数量的短读和长读队列。大于0.5的值表示长读取队列比短读取队列多。值为0或1表示使用相同的队列进行获取和扫描。示例:假设读取呼叫队列的总数为8,则scan.ratio为0或1表示:8个队列将同时包含长读取请求和短读取请求。scan.ratio为0.3表示:2个队列将仅包含长读请求,而6个队列将仅包含短读请求。scan.ratio为0.5表示:4个队列将仅包含长读请求,而4个队列将仅包含短读请求。scan.ratio为0.8表示:6个队列将仅包含长读请求,而2个队列将仅包含短读请求。
默认
0
这几个参数的作用官网解释的还挺详细,按照其中的意思,配置一定比例,就可以达到读写队列,get 和 scan 队列分离的目的,但是,调配参数后,继续如上测试,发现,并不难控制 的线程的数量,发现没毛用。
这里有一个疑问,队列和我所理解的线程池直接到底是什么关系?是否是一个东西?这个之后需要观其源码,窥其本质。
9. 总结
啰啰嗦嗦总算把定位问题的整个过程记录了下来,其实文字描述的还不算很详尽,只是尽可能还原当时的场景和梳理问题的大体思维流程,免得以后遗忘,同时也期望各位同行能从我这里受到点启发,期间也受到了不少大神的提点,在此也特别感谢各方大佬的帮助。
作者 | 介龙平,英文名 leo,码农一枚
———END———
限 时 特 惠: 本站每日持续更新海量各大内部创业教程,永久会员只需109元,全站资源免费下载 点击查看详情
站 长 微 信: nanadh666

