

想进大厂,但不知道该如何入手,不妨从先过八股文的题量开始,比如先过个50题,然后一边面,一边学,进大厂就只不过是时间问题了,加油打工人!
本篇一共10题,大概花20分钟阅读
1. 那些类型是引用类型,那些类型是值类型?
Note: 对于类型,其原类型是引用类型那就也是引用类型,如果其原类型是值类型,那就也是值类型,取决与其原类型。
2. new和make的区别?
拓展:
C语言中,指针和引用的区别,在C语言中,指针和引用的主要区别在于指针指向一个地址后,后续还可以再指向新的地址,而引用一旦指向某个地址后,就不能在修改了,一旦修改就会直接修改之前所引用的变量。
int a= 2,b = 3;
int *ptr = &a,&ptry = b;
ptry = a;
printf("%d %d %dn",*ptr,ptry,b);
output:
2 2 2参考资料:
3.切片和数组的区别?
切片和数组都是用来存储同一类型的数据集合,但是数组是值类型,而切片是引用类型,并且数组不可动态扩展长度,而切片可以自动扩容。切片的底层实现是通过数组来实现的,切片还比数组多了一个cap容量的概念。
4.切片的底层实现是怎么样的?
切片的底层数据结构由指向底层数组的指针,长度以及容量所组成。
type SliceHeader struct {
Data uintptr //指向数组的指针
Len int //长度
Cap int //容量
}5.切片的扩容方式?
当所需容量大于当前容量,就会扩容,当所需容量大于当前容量的两倍时就会直接扩到所需容量,当len > 1024的,就会每次扩25%直到扩到满足所需容量为止,当长度小于1024的时候,就每次扩两倍容量。并且所需容量不同类型的计算方式还不一样,但是可以保证计算出来的所需容量一定大于或等于真实的所需容量。一个int32类型的切片,其cap为0,len为0,一次性添加5个数据的之后,这时cap会为6,而如果是int16类型的则会为8,真实所需的容量是5。
建议先看参考资料的博文,讲得更加详细,以上为总结。
参考资料:
6.切片扩容所引发的问题
当切片扩容时,会开辟一块新的内存空间,把老地址的切片的内容复制到新地址当中,并让原指针指向新的地址空间。这可能会引发如下的问题:
func escape(c []string) {
c = append(c, "1", "2")
}
func main() {
a := make([]string, 0, 2)
a = append(a, "1", "2")
b := a
escape(a)
fmt.Println(a)
fmt.Println(b)
}
output:
[1 2]
[1 2]正常来说切片a和b的输出都应该是1 2 1 2 才对,但是为什么都不是1 2 1 2 呢?那是因为这个函数的切片c发生了扩容,指向了新的地址,而main函数的切片a和切片b还是指向原来的地址,当然数据也就没有被改变。
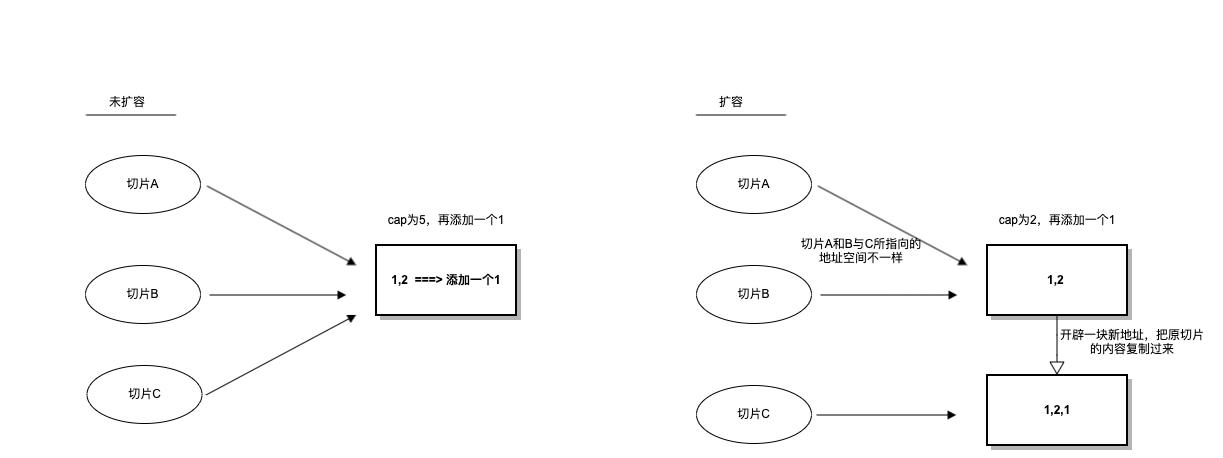
7.如何避免切片发生扩容所引发的坑呢?
1.使用copy函数,copy一个全新的切片
a := make([]string, 0, 2)
a = append(a, "1", "2")
b := make([]string, 0, len(a))
copy(b,a)
a = append(a, "1", "2")2.和一样,去接收所返回的切片
func escape(a []string) []string {
a = append(a, "1", "2")
return a
}
func main() {
a := make([]string, 0, 2)
a = append(a, "1", "2")
b := a
a = escape(a) //去接收返回值
fmt.Println(a)
fmt.Println(b)
}8. 什么是内存逃逸
函数中的一个变量,如果其作用域没有超过该函数,那么该函数的内存就会在栈上分配,否则就会在堆上分配。一个变量的内存到底是在栈上分配,还是在堆上分配,取决于编译器做完逃逸分析之后决定的。
观察这段代码:
func escape() *int {
var1 := 1
fmt.Println(&var1)
return &var1
}
func main() {
data := escape()
fmt.Println(data)
}
output:
0xc000114000
0xc000114000
a1@dxmdeMacBook-Pro golang-test % go tool compile -m flag-study.go
flag-study.go:13:13: inlining call to fmt.Println
flag-study.go:19:13: inlining call to fmt.Println
flag-study.go:12:2: moved to heap: var1 => 变量var1逃逸到堆上了
flag-study.go:13:13: []interface {}{...} does not escape
flag-study.go:18:2: moved to heap: data
flag-study.go:19:13: []interface {}{...} does not escape
:1: .this does not escape这种写法在C++当中是不被允许的,因为()函数返回了一个局部变量的地址,而局部变量在函数执行完成之后会被回收。那为什么在当中却可以呢?这就是内存逃逸现象,当函数中的一个变量其作用域超过了该函数,那么编译器在进行逃逸分析的时候,就会在堆上为这个变量分配内存,变量就由栈上逃逸到堆上了。
Note: 为什么需要我们需要知道这个知识点呢?原来函数内部的变量内存都分配在栈上,随着函数运行完成,栈上的内存也随之被回收,不会给gc带来很大的压力,而如果变量逃逸到堆上去了,只能通过gc来进行内存回收,如果是因为大量变量逃逸到堆上去从而导致gc来不及回收,内存变大,这是一个优化的方向。
参考资料:
9.什么是深拷贝,什么是浅拷贝
深拷贝就是完全复制一个新的对象,新对象与原对象的存储空间完全不一样,而浅拷贝就是复制一个指针,指针仍然指向原对象的内存空间。在中,当我们调用一个函数,传引用类型的时候或者是指针都是浅拷贝,而传其他类型都是深拷贝。
10.调用一个函数传值还是传结构体?
调用一个函数,通常传的是指针,避免深拷贝带来的效率和内存上的消耗,除非我不希望该方法改变我结构体中的内容。接受的话一般接受结构体,避免内存逃逸带来gc上的压力。
Note: 接收参数,gc压力和深拷贝的开销取一个平衡点,其实怎么说应该都不算错,关键是要说明白你为什么要这么做。
———END———
限 时 特 惠: 本站每日持续更新海量各大内部创业教程,永久会员只需109元,全站资源免费下载 点击查看详情
站 长 微 信: nanadh666

