

of Deep with Keras
基于Keras的深度神经网络应用
著:Jeff 译:人工智能学术前沿
目录
1.基础
2.机器学习
3.简介
4.表格类数据的训练
5.正则化和
6.用于计算机视觉的卷积神经网络
7.生成对抗网络
8.数据集
9.迁移学习
10.Keras的时间序列
11.自然语言处理与语音识别
12.强化学习
13./Other
14.其他神经网络技术
2.4 Apply 函数和 Map函数
Part 2.4: Apply and Map
如果你以前接触过大数据或函数式编程语言,你可能听说过map/。Map和是将创建的任务应用到数据帧()的两个函数。支持函数式编程技术,允许您跨整个数据帧使用函数。除了您编写的函数外,还提供了几个用于数据帧的标准函数。
数据帧中Map函数的使用
Using Map with
map函数允许您通过将列中的某些值映射到其他值来转换列。考虑Auto MPG数据集,其中包含一个字段,该字段包含一个介于1到3之间的值,该值指示每一辆汽车的地理来源。我们可以看到如何使用map函数将这个数字原点转换为每个原点的文本名称。
我们将开始加载自动MPG数据集。
import os
import pandas as pd
import numpy as np
df = pd.read_csv(
"https://data.heatonresearch.com/data/t81-558/auto-mpg.csv",
na_values=['NA', '?'])
pd.set_option('display.max_columns', 7)
pd.set_option('display.max_rows', 5)
display(df)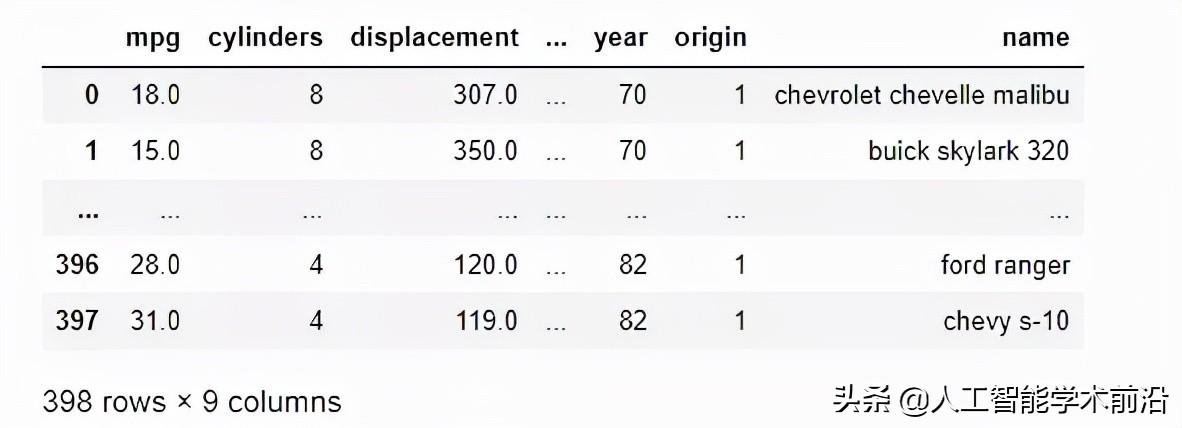
中的map方法操作单个列。为map提供一个值字典,用于转换目标列。映射键指定目标列中的哪些值应该转换为这些键指定的值。下面的代码展示了map函数如何将1、2和3的数值转换为北美、欧洲和亚洲的字符串值。中的map方法操作单个列。为map提供一个值字典,用于转换目标列。映射键指定目标列中的哪些值应该转换为这些键指定的值。下面的代码展示了map函数如何将1、2和3的数值转换为北美、欧洲和亚洲的字符串值。
# Apply the map
df['origin_name'] = df['origin'].map(
{1: 'North America', 2: 'Europe', 3: 'Asia'})
# Shuffle the data, so that we hopefully see
# more regions.
df = df.reindex(np.random.permutation(df.index))
# Display
pd.set_option('display.max_columns', 7)
pd.set_option('display.max_rows', 10)
display(df)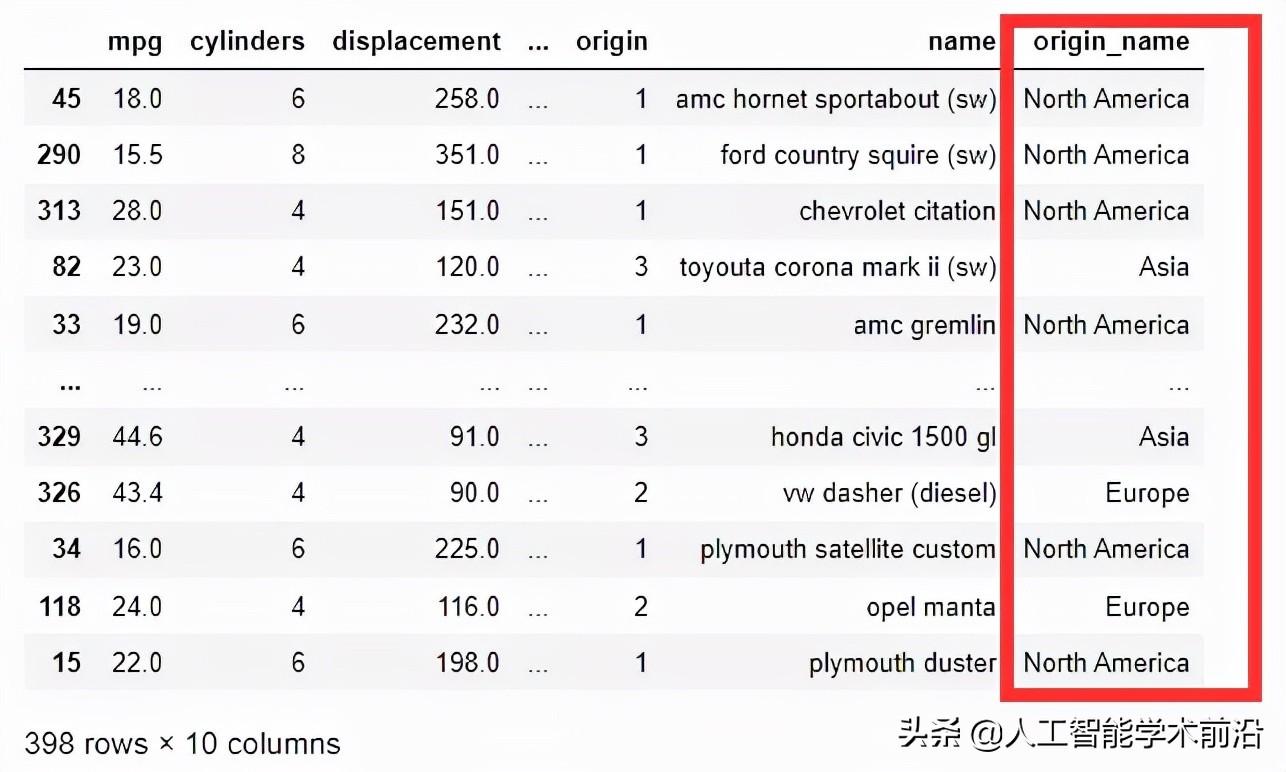
数据帧中Apply函数的使用
Using Apply with
数据帧的apply函数可以在整个数据帧上运行一个函数。您可以使用传统的命名函数或函数。将针对数据帧中的每一行或每一列执行所提供的函数。函数的轴参数指定是跨行或列运行的。对于axis = 1,使用行。下面的代码计算一个称为 的级数,它是除以。
efficiency = df.apply(lambda x: x['displacement']/x['horsepower'], axis=1)
display(efficiency[0:10])输出
45 2.
290 2.
313 1.
82 1.
33 2.
249 2.
27 1.
7 2.
302 1.
179 1.
dtype:
现在,您可以将该系列插入到数据框架中,作为新列或替换现有列。下面的代码将这个新系列插入到数据帧中。
df['efficiency'] = efficiency使用Apply和Map函数的特征工程
with Apply and Map
在本节中,我们将看到如何使用map、apply和分组来计算复杂的特性。数据集为CSV格式:
此URL包含美国政府“SOI税收统计-个人所得税统计”的公共数据。该网站的入口点在这里:
描述该数据的文档位于上面的链接。
对于这个特性,我们将尝试估计每个邮政编码的调整后总收入(AGI)。数据文件包含许多列;但是,您将只使用以下内容:
STATE – 国家(e.g., MO)
– 邮编 (e.g. 63017)
– 年收入的六个不同等级 (1 6)
N1 – 每个的纳税申报单的数量
注意,对于括号中的每个邮政编码,该文件将有六行。您可以跳过邮政编码0或99999。
我们将用这些列创建一个输出CSV;但是,每个邮政编码只有一行。计算收入等级的加权平均值。例如,63017有以下6行:
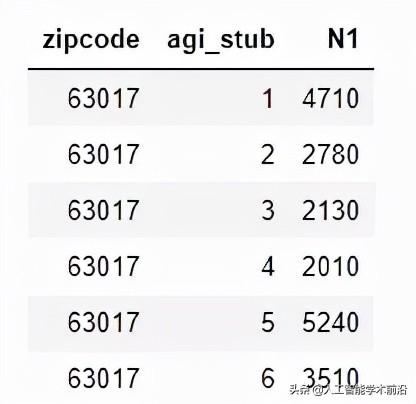
我们必须把这六行合并成一行。出于隐私考虑,AGI被分成6个部分。我们需要将这些桶组合起来,并估计一个邮政编码的实际AGI。为此,考虑N1的值:
1 = 1 to 25,000
2 = 25,000 to 50,000
3 = 50,000 to 75,000
4 = 75,000 to 100,000
5 = 100,000 to 200,000
6 = 200,000 or more
这些范围的中位数约为:
1 = 12,500
2 = 37,500
3 = 62,500
4 = 87,500
5 = 112,500
6 = 212,500
使用这个你可以估计63017的平均AGI如下:
>>> = 4710 + 2780 + 2130 + 2010 + 5240 + 3510
>>> = 4710 * 12500 + 2780 * 37500 + 2130 * 62500 + 2010 * 87500 + 5240 * + 3510 *
>>> print( / )
88689.
我们从读取政府数据开始。
import pandas as pd
df=pd.read_csv('https://www.irs.gov/pub/irs-soi/16zpallagi.csv')首先,我们修剪所有邮政编码0或99999。我们还选择了我们需要的三个字段。
df=df.loc[(df['zipcode']!=0) & (df['zipcode']!=99999),
['STATE','zipcode','agi_stub','N1']]
pd.set_option('display.max_columns', 0)
pd.set_option('display.max_rows', 10)
display(df)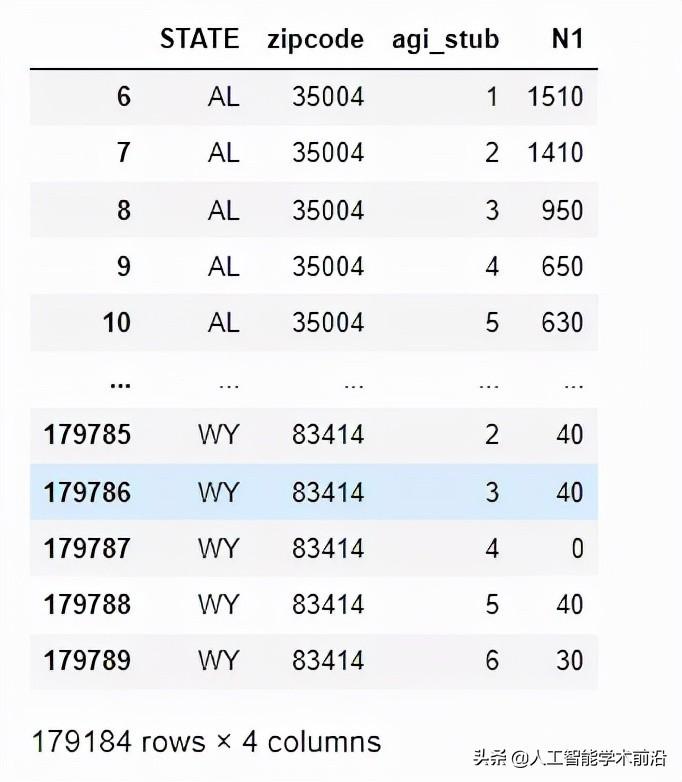
我们使用map函数将所有值替换为正确的中值。
medians = {1:12500,2:37500,3:62500,4:87500,5:112500,6:212500}
df['agi_stub']=df.agi_stub.map(medians)
pd.set_option('display.max_columns', 0)
pd.set_option('display.max_rows', 10)
display(df)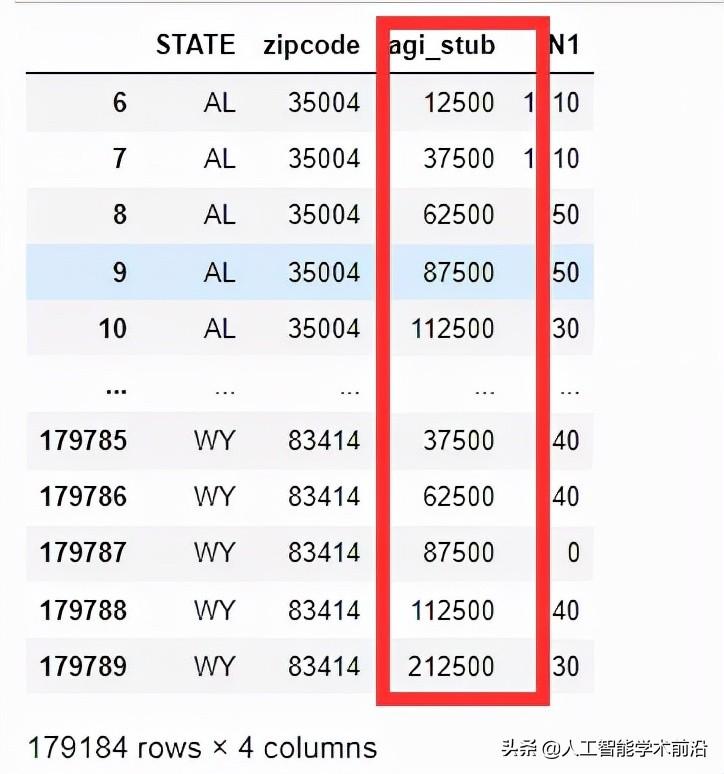
接下来,我们将数据帧按邮政编码分组。
groups = df.groupby(by='zipcode')该程序应用一个在组中应用,然后计算AGI估计。
df = pd.DataFrame(groups.apply(
lambda x:sum(x['N1']*x['agi_stub'])/sum(x['N1'])))
.reset_index()pd.set_option('display.max_columns', 0)
pd.set_option('display.max_rows', 10)
display(df)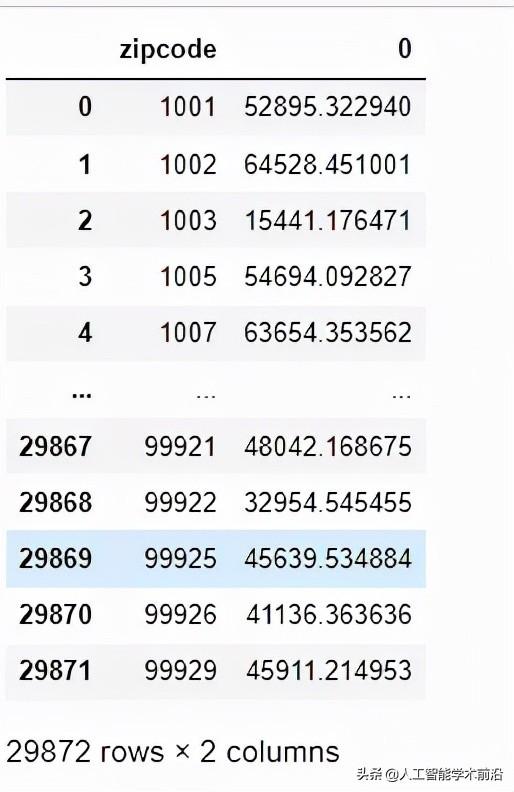
现在可以重命名新的列。
df.clumns = ['zipcode','agi_estimate']pd.set_option('display.max_columns', 0)
pd.set_option('display.max_rows', 10)
display(df)
最后,我们检查63017的邮政编码是否得到了正确的值。
df[ df['zipcode']==63017 ]
———END———
限 时 特 惠: 本站每日持续更新海量各大内部创业教程,永久会员只需109元,全站资源免费下载 点击查看详情
站 长 微 信: nanadh666

