

在统治的AI时代之下,
散落在世界各地的「RNN神教」信徒,一直相信并期待着RNN回归的那天:

毕竟,凭借强大的顺序和上下文感知能力,RNN曾在各种任务中表现惊艳。
直到后来遭遇了反向训练的瓶颈,因 Law而跌落神坛。
然而,人们并没有忘记RNN。
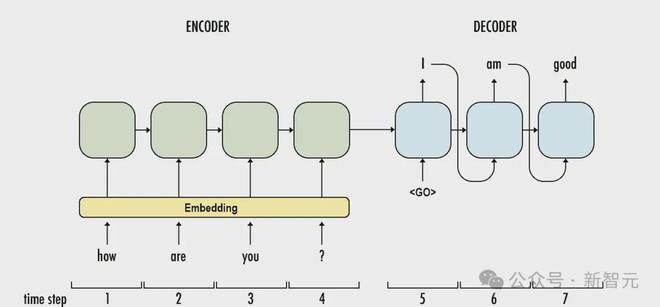
RWKV、Mamba、xLSTM等RNN衍生模型接连出现,欲挑战之霸主地位。
就在近日,又有重量级人物下场——
深度学习三巨头之一的 ,带领团队推出了全新的RNN架构,以大道至简的思想与一较高下。

论文地址:
研究人员对传统的两种RNN架构LSTM和GRU,进行了大刀阔斧的改造,从中诞生了两个新模型:和。
这俩极简主义的版本到底怎么样?咱们先看疗效。
首先是RNN最大的问题:训练速度。
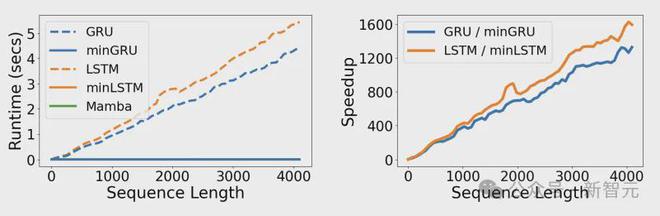
上图展示了几种模型在T4 GPU上训练花费的时间,以及新模型带来的加速比。横轴为输入数据的序列长度,批量大小为64。
可以看到,相比于原版的LSTM和GRU,、和Mamba的运行时间不会随序列长度而增加(后3个模型的线在左图中重叠了)。
当序列长度为4096时,新架构相对于传统版本达到了1300多倍的加速比!
相当于原版GRU需要3年才能做完的事情,一天就搞定了。
那么对线的战绩如何?
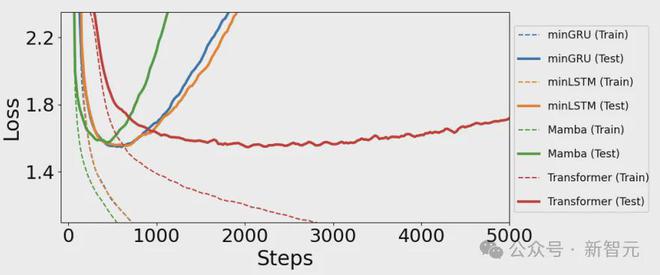
在本文测试的语言建模任务中,和分别在600步左右达到最佳性能点。
相比之下,需要比多花大概2000步,训练速度慢了约2.5倍。
对此,YC上的网友表示:「我非常喜欢这个新架构的简单性」。

毕竟,俗话说的好,「最好的PR是那些删除代码的PR」。
模型架构
下面来感受一下极简模型的诞生过程。
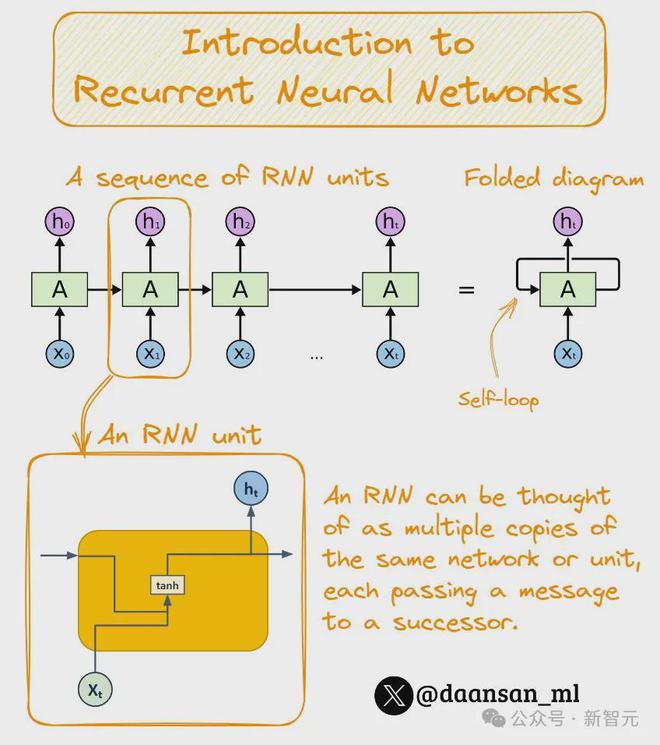
首先,这是传统的RNN架构:
LSTM在RNN的每个cell中加入了比较复杂的门控:
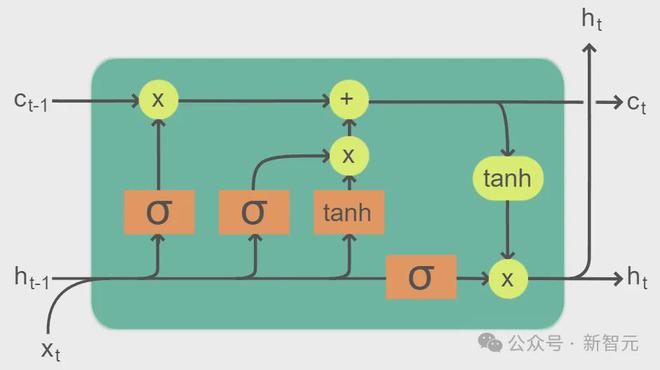
三个门控(input gate、 gate、 gate)和输入的分量,都通过线性投影和非线性激活函数来得出,并且依赖于上一个时刻的隐藏状态ht-1。

这些值再经过线性和非线性计算,得到本时刻的输出ct和隐藏状态ht。
GRU在LSTM的基础上做了一些简化:
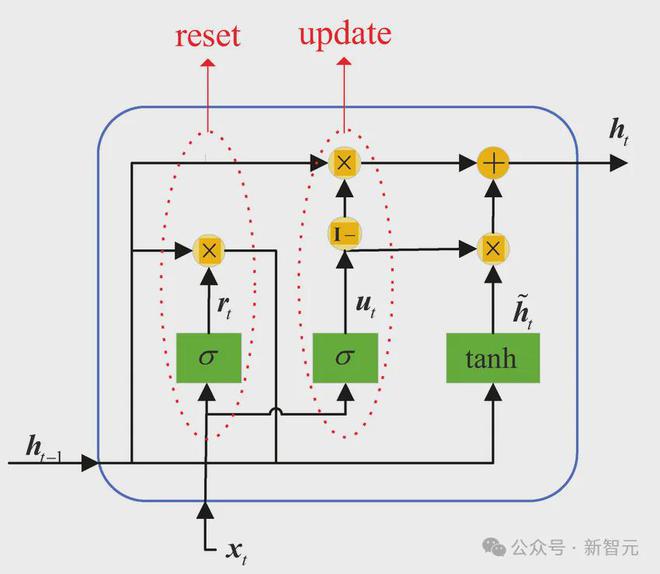
少了显式计算ct,用于门控的项也缩减到2个,相应的参数量和计算量也减少了。
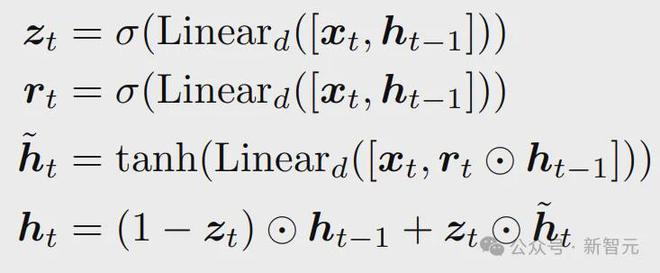
那么我们就从相对简单的GRU入手,开始改造。
改造的目的是使RNN能够应用并行扫描( Scan)算法,解决自身训练困难的问题。
简单来说,就是将网络中的计算改造成vt = at ⊙ vt−1 + bt的形式。
第一步,公式中含有对之前隐藏状态ht-1的依赖,没办法用并行扫描,所以把ht-1直接删掉。
ht-1没了,负责调控ht-1的rt也没用了,删掉。
第二步,双曲正切函数(tanh)负责限制隐藏状态的范围,并减轻因(σ)而导致的梯度消失。
但是现在ht-1和rt都没了,tanh也失去了存在的意义,删掉。
那么最终,就是下面这三个公式:
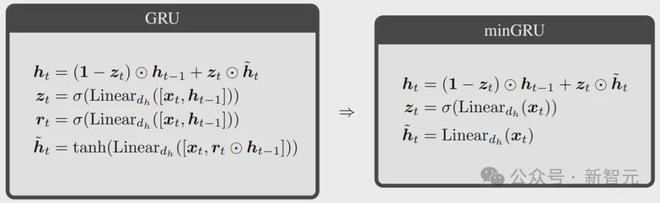
相比于原版,参数量和计算量再次减少,最重要的是能够使用并行扫描来显著加快训练速度。
经过上面的叙述,的由来就很好理解了。
首先还是去除隐藏状态的依赖:
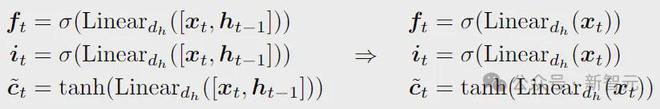
接着是拿掉相关的tanh:
最后,为了保证LSTM输出的尺度与时间无关,以及 state在缩放上与时间无关,还需要删掉 gate。
gate没了,ct也就没必要单独存在了,删掉;剩下的两个门控通过归一化来调配 state进入的比例。
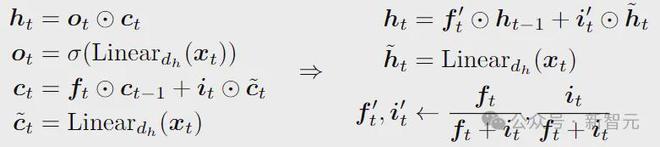
——emmm……好像变成GRU了,算了不管了。
最终改造好的是下面这个样子:

Were RNNs All We ?
全新的RNN搞出来了,能打吗?
别急,先打内战证明价值。
除了传统的RNN(LSTM和GRU),这里特别关注与Mamba的比较。
首先是训练上的提升:
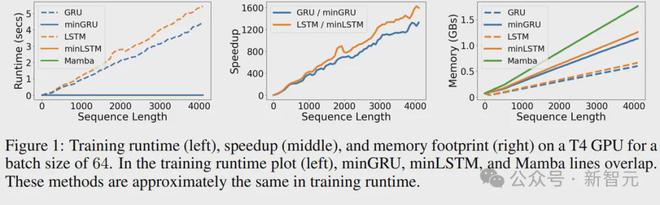
实验在批次大小64的情况下改变序列长度,测量了模型执行前向传递、计算损失和向后传递计算梯度的总运行时间以及内存占用。
在运行时间方面,、与Mamba实现了类似的效率。
序列长度为512时的运行时间(超过100次的平均值),分别为 2.97、2.72和2.71毫秒;序列长度为4096时,运行时间分别为3.41、3.25和3.15。
相比之下,LSTM和GRU的运行时间随序列长度线性增加。所以序列长度为512时,和的训练加速了175倍和235倍;序列长度为4096时,加速比达到了1324和1361。
内存方面,利用并行扫描算法时会创建更大的计算图,所以、和Mamba ,比传统RNN需要更多的内存(大概多出88%)。
——但这并不重要,因为对于RNN来说,训练时间才是瓶颈。
去除隐藏状态的效果
和的训练效率是通过降低它们的门控对先前隐藏状态的依赖来实现的。
尽管单层或的门控只与输入有关,而与时间无关,但是在深度学习中,模型是通过堆叠模块来构建的。
从第二层开始,和的门也将与时间相关,从而对更复杂的函数进行建模。
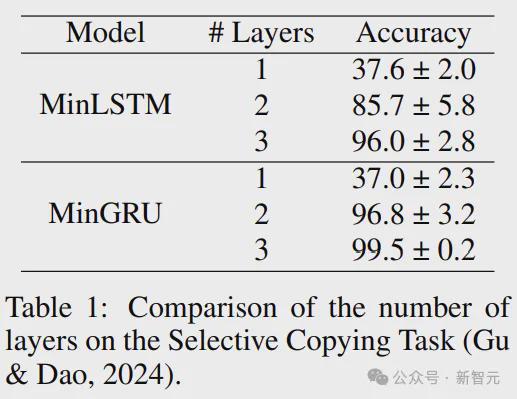
下表比较了不同层数的模型在选择性复制任务上的性能。我们可以看到时间依赖性的影响:将层数增加会大大提高模型的性能。
训练稳定性
层数的另一个影响是稳定性,随着层数的增加,精度的方差减小。
此外,尽管和都解决了选择性复制任务,但我们可以看到在经验上是一种比更稳定的方法(更高的一致性和更低的方差)。
丢弃旧信息并添加新信息,使用两组参数( gate 和input gate)控制比率。在训练期间,两组参数会向不同的方向进行调整,使得比率更难控制和优化。相比之下,的丢弃和添加信息由一组参数控制,更容易优化。
选择性复制
选择性复制任务的输入元素相对于其输出是随机间隔的,为了解决这项任务,模型需要执行内容感知推理,记住相关token并过滤掉不相关的token。
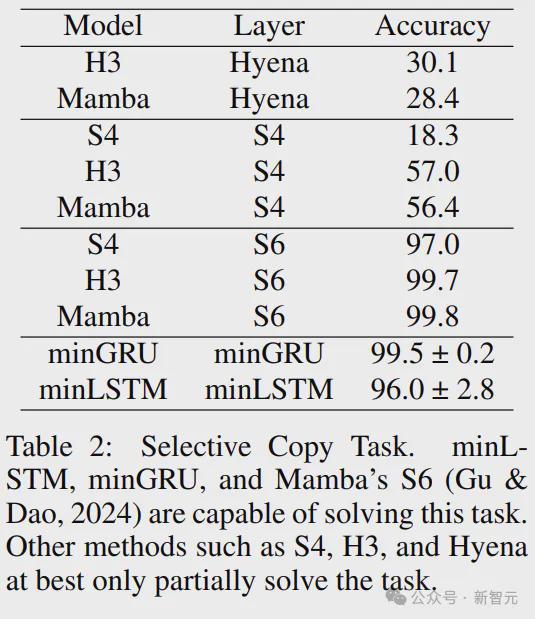
上表将和与可以并行训练的知名RNN模型进行了比较(S4,H3,Hyena和Mamba(S6)),基线结果引自Mamba论文。
在所有这些基线中,只有Mamba的S6,以及本文的和能够解决此任务,体现了LSTM和GRU的内容感知门控机制。
强化学习
下面开始对战。
考虑D4RL基准中的运动任务,包括三个环境:、和。
对于每个环境,模型在三个数据质量不同的数据集上进行训练:(M)、-(M-R)和-(M-E)。
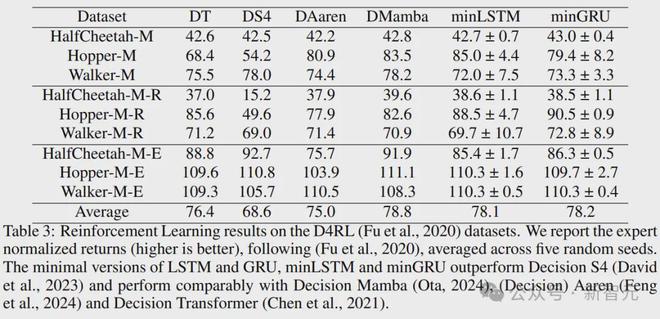
上表将和与各种决策模型进行了比较,包括原始的 (DT)、 S4 (DS4) 、 Mamba和Aaren。
由结果可知,和的性能优于 S4,与 、Aaren和Mamba相媲美( S4的递归转换不是输入感知的,这会影响它的性能)。就平均分数而言,和的表现优于除 Mamba之外的所有基线。
语言建模
最后考虑语言建模任务,使用框架在莎士比亚的作品上训练字符级GPT。
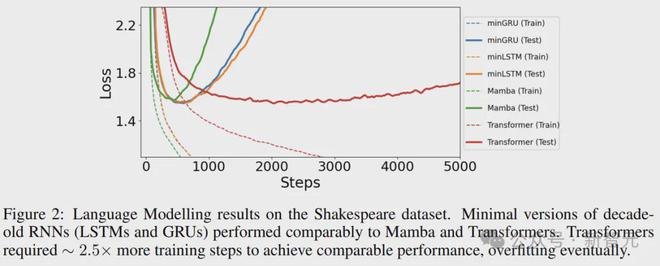
上图绘制了具有交叉熵损失的学习曲线,可以发现、 、 Mamba和分别实现了1.548、1.555、1.575和1.547的可比测试损耗。
Mamba的表现略差于其他模型,但训练速度更快(400步),和分别花费575步和625步。而直接比多了2000 步,慢了大概2.5倍。
参考资料:
———END———
限 时 特 惠: 本站每日持续更新海量各大内部创业教程,永久会员只需109元,全站资源免费下载 点击查看详情
站 长 微 信: nanadh666

